
For the past year, the majority of SaaS companies have been crafting and executing their strategies for the agentic era.
It only takes a quick glance to realize that the default strategy has been embedding conversational AI agents inside existing products. The product (UIs, workflows, etc) stays at the center and agents are just a new layer on top.
But as general-purpose assistants have gotten dramatically more capable—better models, richer ecosystems, connectors, plugins—the direction of the forces is starting to flip.
We're seeing that users are no longer being pushed toward the product and occasionally chatting with an assistant. Instead, they're being pulled into Claude and ChatGPT and only (if ever) occasionally reaching the product.
Many SaaS companies sitting on strong proprietary data and predictive algorithms are starting to base their new AI strategies on this new pattern. The product as we know might soon no longer be the place where work gets done.
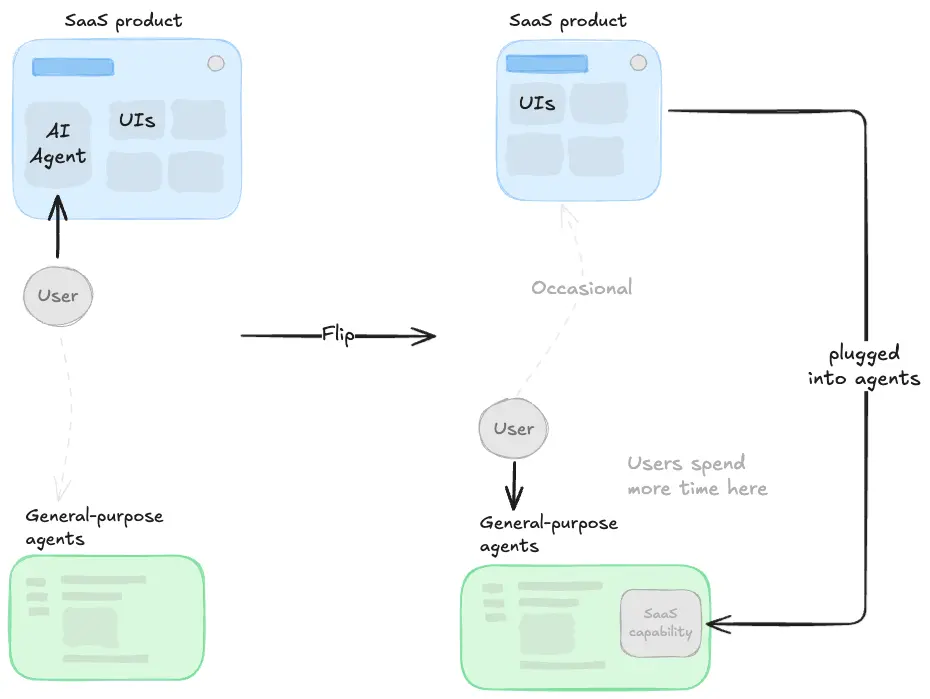
How we think this plays out
Not overnight, but we think successful SaaS companies in the "data-heavy" category will likely move through four phases:
| Phase | Key drivers |
|---|---|
| Phase 1: Continue the original strategy |
|
| Phase 2: Start implementing the Embrace strategy in parallel |
|
| Phase 3: The traditional SaaS product takes a secondary role |
|
| Phase 4: Full convergence |
|
It's impossible to predict exactly when or even if this eventually realizes fully. We're still in the early days of phases 1 and 2. But the market is already signalling that assistant integration might soon become the primary distribution strategy.
1. Context and action layers
The core question for any SaaS company pursuing the "assistant-native" strategy is:
What does it actually take to convert your product into a capability engine for Claude or ChatGPT?
Everyone who has tried to build something like this knows that exposing data and functionality through an API isn't enough. General-purpose agents are powerful reasoners, but they have no idea what your data means (at least before they spend time and compute exploring it), how your customers think about it, or what business rules constrain how it should be used.
Example. A supply chain manager asking Claude to "rebalance safety stock for all slow-moving SKUs in the EMEA region" needs the assistant to understand what "slow-moving" means in terms of inventory turnover thresholds, what "EMEA region" maps to in the warehouse hierarchy, and what approval rules exist around stock level changes.
We set out to close this gap and the result is an infrastructure built around two distinct layers:
- The context layer is built around what we call the Semantic Data Layer (SDL): a persistent knowledge store that holds semantically enriched schemas, metric definitions, terminology mappings, business rules and user experiences. It's exposed through an agent-agnostic connector with MCP tools for discovery, search, entity resolution, and read-only queries. Beyond this structured knowledge, the context layer also carries operational rules from domain experts and individual user preferences.
- The action layer provides the operational tools that let agents take actions on the SaaS platform. These are exposed as connectors and seamlessly integrated alongside the context layer. From the assistant's perspective, context and action tools look like a unified toolkit but the boundary is deliberate. Existing APIs just need to be wrapped as MCP endpoints, and the context layer provides the semantic glue that makes them usable in natural language.
The key insight is that neither layer alone is sufficient. Context without actions means an assistant that understands your data but it's an insights-only agent. Actions without context means an assistant that has powerful tools but doesn't know when or how to use them correctly.
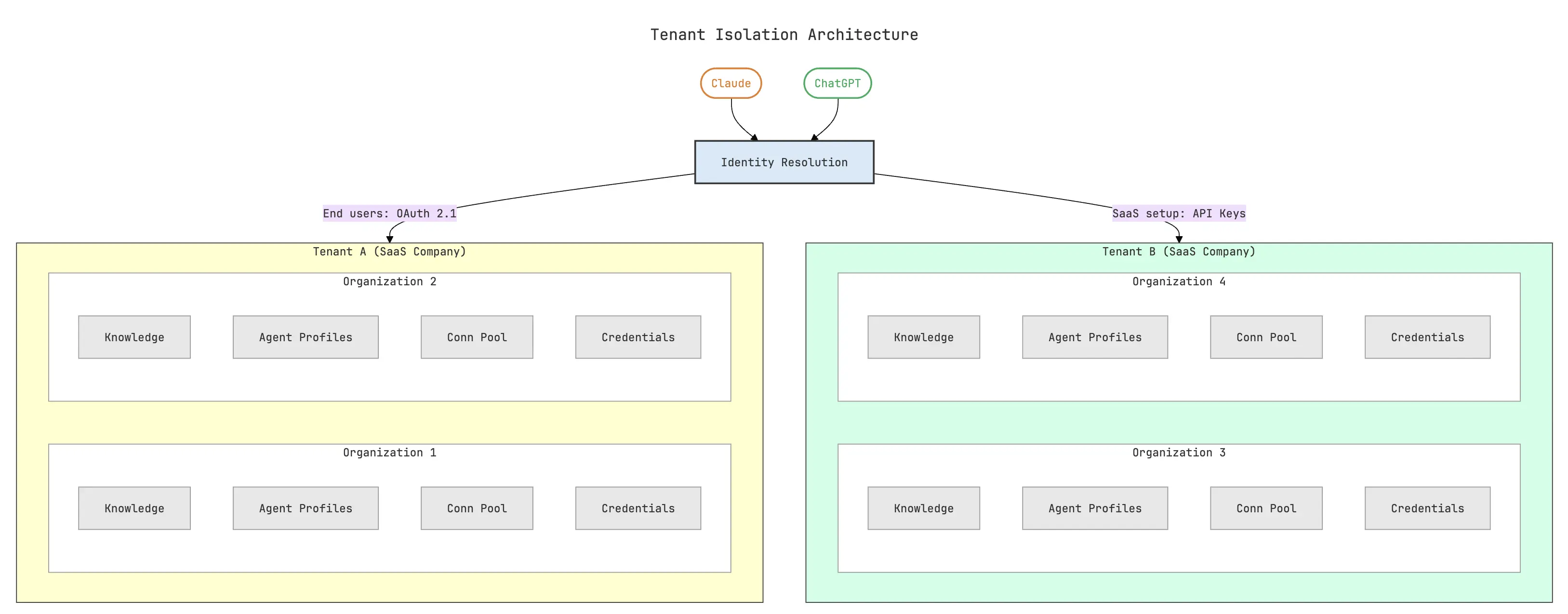
2. Multi-tenancy
Our context layer is multi-tenant by design. This is a hard requirement for B2B SaaS companies. Each customer, and each of their customers, has their own data, their own vocabulary and their own business rules.
Example. A demand forecasting platform used by a fashion retailer and a pharmaceutical distributor can't share the same context even if the underlying data model looks similar, since "seasonality" means completely different things.
But most importantly, Customer A's agent must not have the ability to access Customer B's data for data-privacy reasons.
The SDL handles this through strict tenant and organization isolation. Every request that hits the SDL resolves to a specific tenant (the SaaS company) and organization (their customer) so data, knowledge, agent profiles, and credentials can never cross boundaries.
Authentication follows a dual strategy:
- SaaS companies authenticate via API keys during setup and ingestion—when they're configuring the knowledge layer for their customers.
- End users authenticate via OAuth 2.1, the same flow they're used to in any modern app. When a pricing analyst installs the plugin in Cowork and signs in, the OAuth flow resolves their identity, their organization, and scopes every subsequent interaction to the right data.
3. Domain specialization
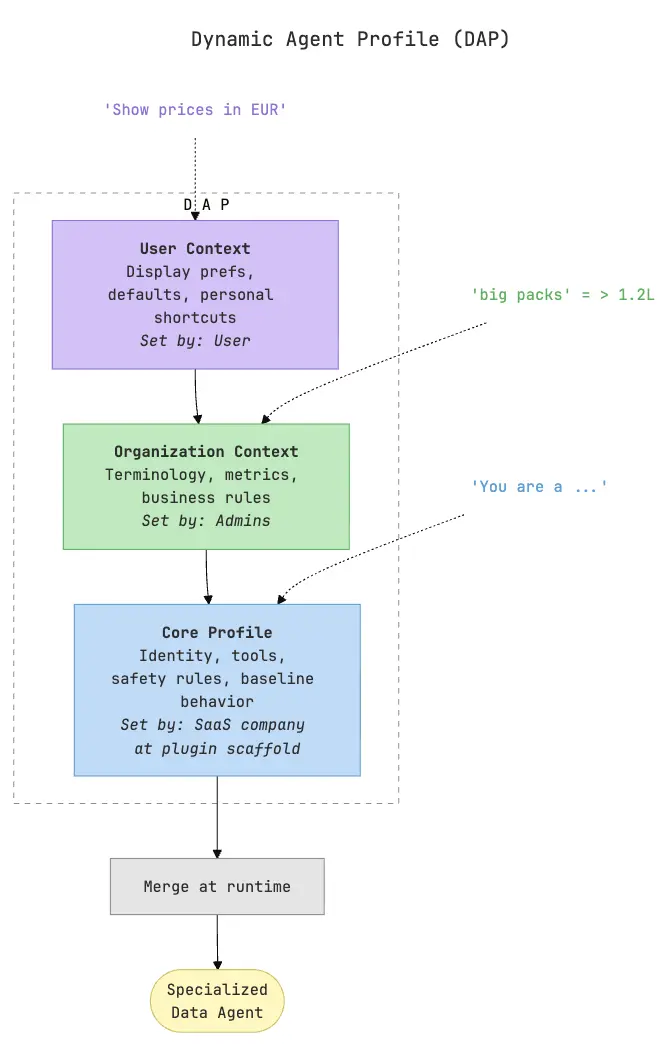
We also created the Dynamic Agent Profile (DAP). It's a three-layer configuration system that progressively specializes assistants like Cowork or ChatGPT into a domain-specific data agent:
- The first layer is the core profile: generated when the SaaS company scaffolds a plugin with its connector and skills. It defines the agent's identity, which MCP tools are available, safety rules, and baseline behavior. e.g. it establishes the agent as a supply chain or a revenue operations assistant, rather than a general assistant that happens to have some domain tools.
- The second layer is organization context: shared knowledge and rules specific to one customer. This is where domain terminology lives ("when we say 'at-risk accounts' we mean accounts with NPS below 6 and declining usage over 3 months"), where metric definitions are stored ("churn risk score is calculated as..."), and where business rules are enforced ("never trigger automated outreach to enterprise accounts without CSM approval"). This layer is maintained by the SaaS company's team or by designated admins at the customer organization, and it applies to everyone in that org.
- The third layer is user context: personal preferences that individual users set for themselves. One analyst might want prices displayed in EUR with two decimal places. Another might want results grouped by retailer by default. These preferences don't override organizational rules.
At runtime, when an assistant makes a request to the SDL, these three layers merge into a single effective agent profile.
The power of this approach is that the agent gets better over time without anyone rebuilding prompts or redeploying anything:
- A new business rule added to organization context immediately changes how every user's assistant behaves.
- A personal preference set by one analyst only improves their experience.
- The core profile can be updated by the SaaS company across all their customers at once when they ship new capabilities.
4. Scaffolding and distribution of plugins
Ease of distribution is another hard requirement, and we built our infra with that in mind. The plugin scaffolding system is designed to take a fully configured SDL—with multi-tenant auth, knowledge stores, agent profiles, and MCP integrations—and package it into something any user can install in Cowork or ChatGPT with one click.
The scaffolding command generates a complete plugin directory:
- Authentication configuration (pre-wired OAuth client)
- The SDL connector
- The company's operational MCP endpoints
- A set of skills that define how the agent should interact with users
The output is a branded plugin that looks and feels like it was built from scratch for that specific product.
From the end user's perspective, the experience is: install the plugin, sign in with their existing credentials, and start working.
5. Continuous learning
In the real world, business rules change, new tables are added to databases, terminology and user preferences evolve, etc. As I've already hinted above, the context layer addresses this through multiple learning channels, each designed for a different type of knowledge evolution.
Domain teaching
/teach is a structured onboarding flow skill for domain experts, who is typically someone from the SaaS company's customer success team or a power user at the customer organization. It walks through the business landscape, captures metric definitions and business rules, and persists everything to the organization context. This is how the heavy lifting of domain knowledge gets into the system, and it's designed to feel like a conversation rather than a data entry form.
Correction submission
/submit-correction handles the inevitable case where the agent gets knowledge wrong in production. Rather than ignoring the mistake or filing a support ticket, users can flag it directly. The correction enters a review queue where domain experts can approve, reject, or refine it before it becomes part of the knowledge layer. This is important for trust.
There is also an LLM-based system that analyses the existing knowledge for conflicts. This system can also surface internal conflicts. e.g. the company's organizational knowledge defines a formula for calculating a metric but all users of that organization keep correcting the agent with a different formula.
The result is a knowledge layer that compounds over time. Every user interaction is a potential signal that could make the agent more accurate.
User preferences
/personalize lets individual users teach the agent how they work. "When I say 'big packs' I mean above 1.2L." "Default to retailers 1 and 2 when I don't specify." These are stored in the user context layer and apply only to that user's sessions. The barrier to contribution is deliberately low, so users naturally teach the agent their shortcuts, and the agent gets more efficient with every preference set.
Closing thoughts
For data-intensive SaaS companies, this is a genuinely new distribution surface where your product reaches users inside the tools they already live in, without asking them to context-switch. The companies that explore this early get to shape how their domain works inside assistant interfaces, build compounding knowledge layers, and learn what their customers actually need from this new interaction model.
We're working with SaaS companies to make their products assistant-native. If your product sits on strong proprietary data and you're curious about what this could look like, we'd love to show you a working implementation tailored to your domain and have a real conversation about your product.
Get in touch or reach out directly at bernardo@flow-ai.com.


