On February 12th, at the "Context is King" meetup we co-organized with Aiven, I talked about a problem we had been working on for most of the year at Flow AI.
We wanted data agents that stayed fast and accurate even when the tasks stopped being small.
At first we treated this mostly as a model problem. Better prompts, better planning, better tool use. Some of it was that. But a surprising amount of the slowdown came from something more ordinary: the agent was spending too much time carrying data around.
Once we noticed that, the rest followed fairly naturally.
Where the time goes
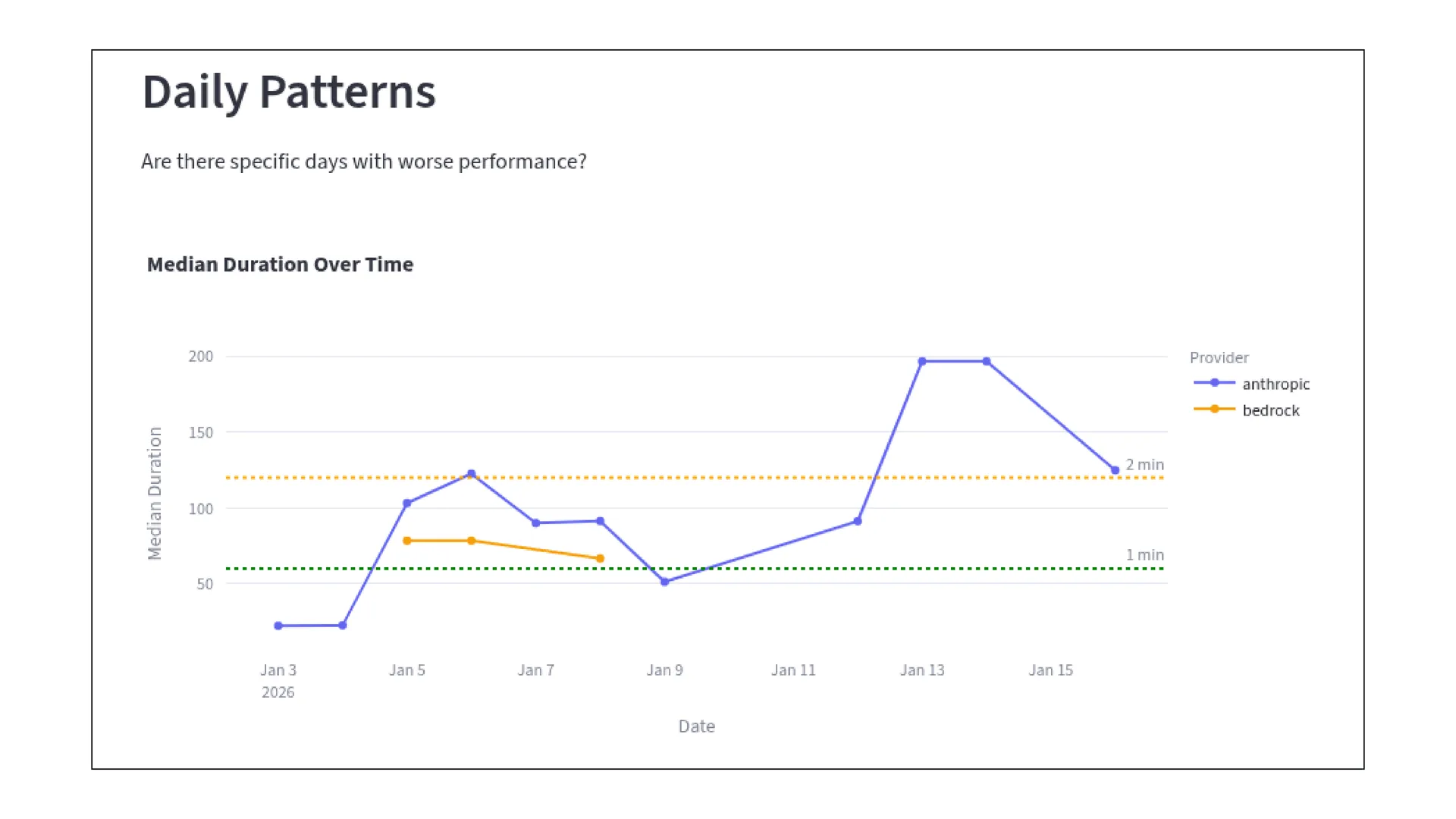
When you build agents for analytical work, the trajectories usually get longer as the requests get more complex. That part is expected.
What was less obvious, at least to us at first, was how much of that extra time had very little to do with reasoning.
A natural-language request can still look compact. Increase one brand by 10%. Exclude some channels. Leave a few product families alone. Respect customer-specific constraints. Make the result reviewable before execution.
The executable version of that request is not compact anymore. It turns into exact product IDs, intermediate result sets, validation outputs, action lists, and sometimes correction loops.
That means the agent is doing two jobs at once.
First, it has to decide what to do next.
Second, it has to act as a courier, moving large intermediate results from one tool call to the next.
That second job is where things start to slow down. A search tool returns a large product set. The model carries it forward. Another step needs the same set, so it gets copied again. Then a validation step looks at it. Then an execution step needs it too. Before long, the context window is full of UUIDs and payloads that are not really part of the decision.

That turned out to be the basic shape of the problem for us. The tasks were getting more complex, yes. But the context window was also filling up with data that only happened to be there because the model had become the transport layer.
What did not help much
Once the context window starts filling up, there are a few obvious things people try.
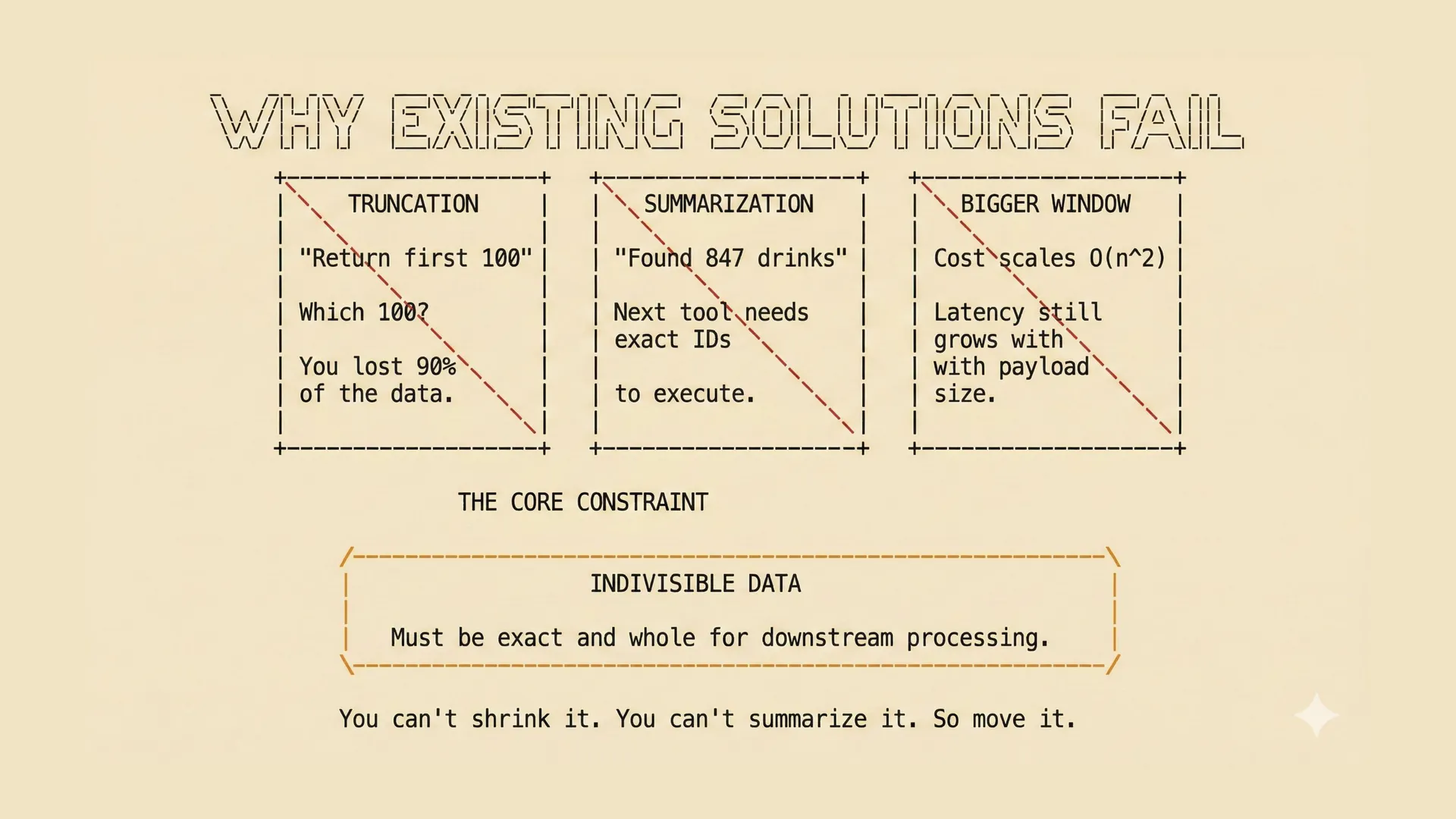
| Approach | How it works | Why it does not really solve this problem |
|---|---|---|
| Truncation | Drop part of the context | Fine until the dropped part is the exact data the next tool call needs. |
| Summarization | Replace the raw result with a summary | Useful for reasoning, but not enough for execution when exact IDs matter. |
| Bigger windows | Use a model with more context | Helps for a while, but the model is still doing storage and transport work it should not be doing. |
The difficult part is that some data is indivisible.
If a downstream step needs the exact set of product IDs, then "847 matching drinks" is not a substitute. It may be a perfectly good summary for a person. It is not an executable payload.
Larger context windows help less than people sometimes hope for the same reason. You are still mixing two different concerns in one place. The model is supposed to reason about the task, but it is also being used to carry around bulky intermediate state.
That does work, in the sense that it eventually works. It just does not scale very gracefully.
A language model is a good place to make decisions. It is not a very good place to park a thousand product IDs while waiting for the next tool call.
Using pointers instead
The design change was simple.
Instead of returning the full result set to the model, we store that result elsewhere and return a reference to it.
When a search tool finds matching products, it writes the exact set into a key-value store and returns a short pointer. So instead of giving the model a thousand UUIDs, the tool returns something like ps-8f35a1c9d0e7.
That pointer is enough for later tool calls to find the same set again. It is not meant to be human-readable, and it is not meant to be executed directly by the model. It is just a compact handle.
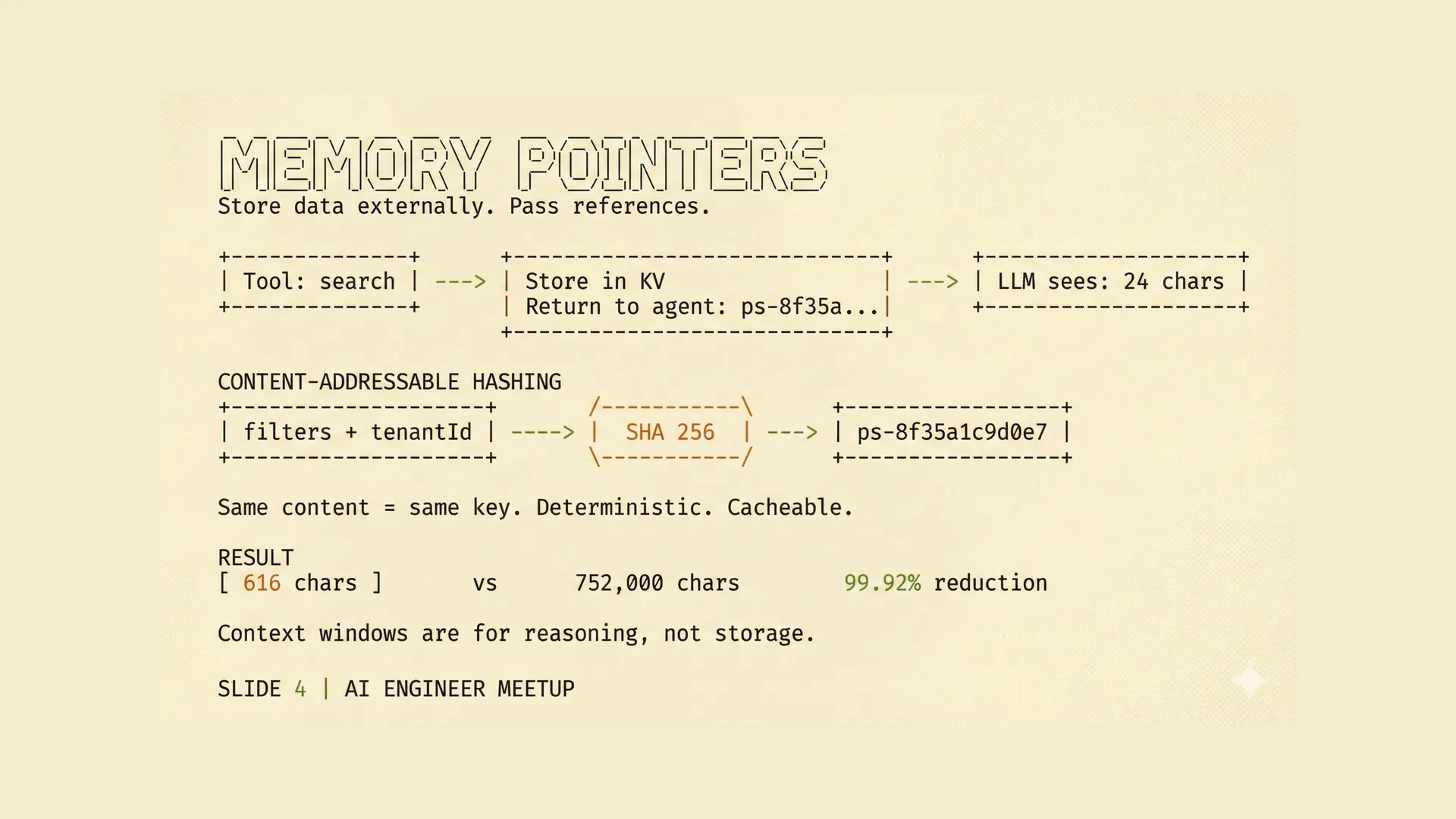
We generate these keys using SHA-256 over the filter conditions plus the tenant ID.
That gives us a few useful properties at once:
- the same logical result set gets the same key
- retries can reuse previous results
- tenants stay isolated from each other
- the model no longer has to drag the raw set through every step
The exact hash function is not the important part. The important part is the split.
The context window is for reasoning.
The storage layer is for state.
Once we started drawing that line more strictly, a lot of the rest of the system got easier to reason about.
Why glimpses matter
A pointer alone is not enough.
If you replace the raw data with an opaque reference, then the model no longer knows what that reference points to.
A token like ps-8f35a1c9d0e7 is useful to the machinery, but it tells the model almost nothing. The model cannot tell whether the set is tiny or huge, whether it spans one brand or five, whether it looks plausible, or whether the next step is acting on the right scope.
So we ended up returning two things, not one.
The first is the pointer.
The second is what we call a glimpse.
A glimpse is a small structured summary of the underlying set: counts, distributions, ranges, top categories, top brands, or whatever else the model actually needs in order to make sensible decisions about that set.

The glimpse is for reasoning.
The pointer is for retrieval.
That combination turned out to matter quite a bit. If you only have the pointer, the model is reasoning blind. If you only have the summary, the system cannot execute precisely. You need both.
What changed
Once we stopped passing raw product sets through the context window, a few other things improved more or less automatically.
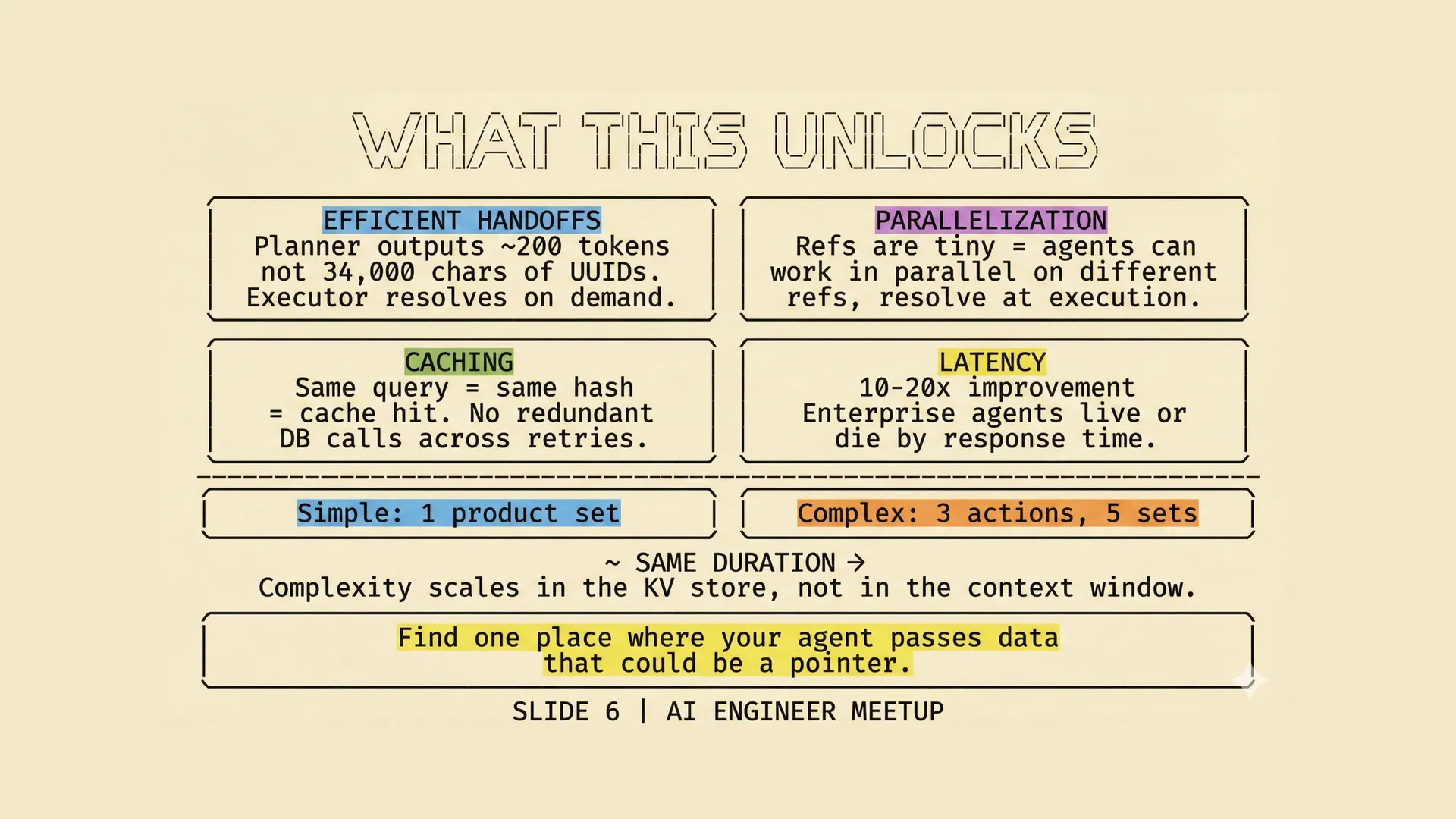
| Benefit | What changes |
|---|---|
| Smaller handoffs | Planner and executor exchange pointers and glimpses, not giant payloads. |
| Parallel work | Multiple agents or steps can refer to different stored sets without copying large arrays through context. |
| Caching | The same query produces the same key, so retries and repeated steps can reuse earlier work. |
| Lower latency | In our traces, end-to-end latency improved by roughly 10–20x. Simple cases fell under 5 seconds, and much larger plans stayed in the same rough range instead of stretching into minutes. |
This does not make every hard problem easy.
If the actual reasoning is hard, then it is still hard. If the constraints conflict, the model still has to notice that. If the planning logic is weak, this does not magically fix it.
What it does do is remove a lot of accidental work. The model spends less time carrying data around and more time doing the part only the model can do.
One implementation detail is worth mentioning here because it is easy to get wrong.
If each tool call creates its own little KV connection or its own isolated state path, then some of the benefit disappears. The tools need to share the same storage layer properly, through a sensible dependency-injected runtime, so that intermediate state moves naturally from one step to the next.
Otherwise you have mostly just invented a more elaborate way to be inefficient.
What to look for in your own traces
The easiest place to start is not architecture. It is traces.

When you look at a trace, these are the four questions worth asking:
-
Which tool calls are returning raw data into context? Arrays, IDs, blobs, large intermediate payloads.
-
Which of those are indivisible? The parts that cannot be truncated or turned into prose without losing executability.
-
What does the model actually need in order to reason about that data? Usually not the raw rows. More often counts, ranges, distributions, and a compact structured summary.
-
Where is data being handed from one step or one agent to another? Those handoffs are often where a pointer boundary wants to exist.
That last one is especially useful.
A surprising number of agent systems are not really failing because the reasoning is too hard. They are failing because the handoffs are messy. Large payloads get dragged through places where a reference would have done, and the context window quietly turns into a storage bus.
If the model needs to understand the shape of a set, give it a glimpse.
If a later tool needs the exact set itself, give the model a pointer.
That is the line we now go looking for.
The pattern is not complicated. The hard part is noticing you need it. Most agent systems do not fail because the reasoning is too ambitious. They fail because the plumbing is doing work the model should never have been asked to do. Once you move the storage job out of the context window, the reasoning job gets a lot easier to improve on its own.
We are building these ideas into Flow AI's agent infrastructure because they keep showing up in real systems. If you are working on data-heavy, customer-facing agents and running into similar problems, we'd be glad to compare notes.


