
In recent years, and especially in recent months!, the landscape of Natural Language Processing (NLP) and Generative AI has witnessed a massive leap forward with the advent of increasingly sophisticated language models. Among these game-changers, we have:
- Developed by Open AI → GPT-3, InstructGPT, GPT-3.5-Turbo, GPT-4
- Developed by Google → LaMDA, PaLM
- Developed by Meta → LLaMA
- Developed by HuggingFace and BigScience Group → BLOOM
Many of these LLMs have been making headlines for not only their remarkable capabilities in text generation but also their ability to perform almost any type of task ranging from simple classification to passing some of the most challenging exams in the world:
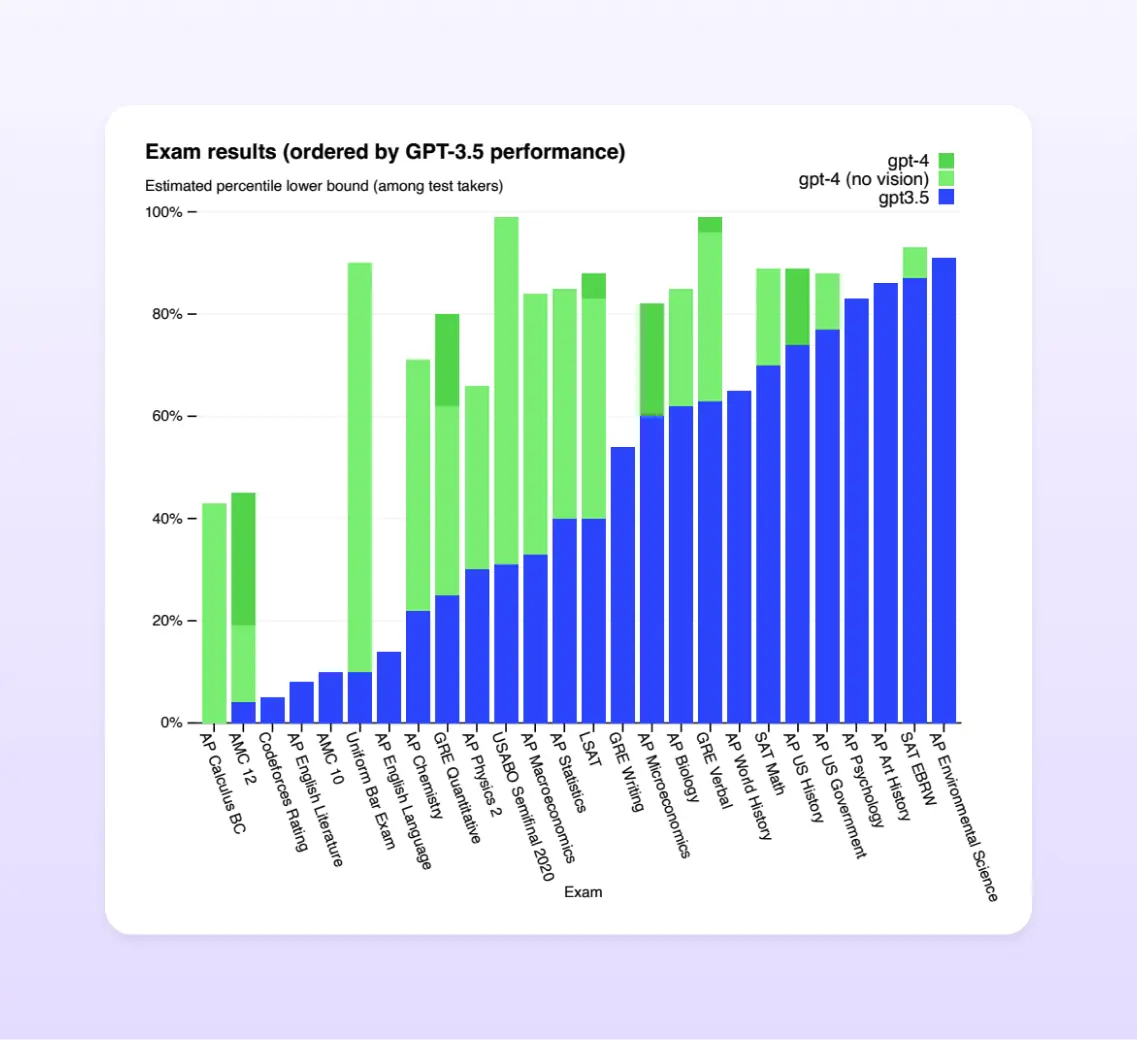
It is true that in certain contexts, some LLMs can be more intelligent than you! However, there is no need to be overly concerned. These models still require your input and will not completely replace all jobs in the world. Instead, LLMs will only bring about change and increase the efficiency of professionals ;)
But I am not going to talk about any LLM in particular. We are going to deep dive into Prompt Engineering and share some tips from our experience building Flowrite during the past 2 years.
Disclaimer - Even though this is a blog post about engineering and technical concepts, I have written this post in a way that aims to be accessible to any audience, regardless if you have a technical background, are familiar with AI, or have no clue. AI is being democratized so it can positively impact any industry. I am going to keep the same direction here.
Prompt Engineering has been increasingly becoming a precious skill since all these extremely powerful LLMs have something in common, they need to be prompted with text to perform any task. Regardless if you are trying to perform a simple classification task or you are building a prompt for a complex Q&A system, your prompt will guide the model to perform the task you are after.
So first things first, What’s a Prompt? In simple words, a prompt is a piece of text that triggers a specific response or action from an LLM. The goal of a prompt is to guide the model's behavior, and we can do that by using different prompting techniques.
# Example of a prompt for summarising meeting notes into bullet points using an instruct model (text-davinci-003). Output in bold font.
---
Extract the most important information in the meetings notes and convey it into bullets points:
{meetings_notes}
Bullets points:
---
Extract the most important information in the meetings notes and convey it into bullets points:
Date: June 12, 2019
Time: 2:00 PM
Attendees:
John Smith
Jane Doe
Robert Johnson
Agenda:
1. Discuss upcoming project deadlines
2. Review progress on current project
3. Brainstorm ideas for new projects
Meeting Notes:
John opened the meeting by discussing upcoming project deadlines. Jane provided a timeline and identified which steps needed to be completed by when. Robert suggested that the team focus on one project at a time to ensure deadlines are met.
The team then reviewed the progress on the current project. Jane reported that the project was on track and that the team was on schedule. John suggested that the team brainstorm ideas for new projects. Robert provided a list of potential ideas and the team discussed each one in detail.
The meeting ended with the team agreeing to focus on completing the current project and to revisit the ideas for new projects at the next meeting.
Bullet points:
- Discussed upcoming project deadlines
- Reviewed progress on current project
- Brainstormed ideas for new projects
- Agreed to focus on completing current project and revisit ideas for new projects at next meeting
As you can see in the prompt above, we are instructing the model to perform an information extraction task. Then, we are passing the meeting notes in an input variable called {meeting_notes}.
With this prompt, an LLM, and a bit of code, we could very easily create a small application that takes meeting notes and produces bullet points with the most important information discussed during the meeting!
Alright, we can now say that we’ve engineered a prompt! Prompt Engineering is a new paradigm in the NLP field. Before we had these large pre-trained language models, the defacto approach was to take a pre-trained model and fine-tune it to a downstream task.
We are currently seeing a shift from “pre-train and fine-tune” to “pre-train, prompt and predict” as mentioned in the paper Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.
With the help of carefully engineered prompts, we can change the pre-trained model behavior to perform a task that the model has not been specifically trained on.
So the goal of Prompt Engineering is to find the best prompt that allows an LLM to solve the task at hand. In the realm of text-generative AI, providing suitable prompts can make all the difference in the quality and relevance of the generated content.
Although Prompt Engineering can be seen as a combination of art and science. There are some well-known prompting methods and we’ll see some of them.
Text generation and Prompt Engineering at Flowrite
Let's deep dive into some of the Prompt Engineering techniques that we’ve used when building Flowrite, an AI-powered email assistant.
At the beginning of 2023, we launched a feature that automatically provides reply suggestions to emails without any action required from users. Here's a quick demo of the feature in action:
In order to produce these suggestions, we use the following inputs:
- The received email for which we want to produce suggestions
- User’s identity data like the company that the user work for or a description
We can classify this task as a type of open-ended text generation, where we have limited information about the conversation or the users’ reply intents and there are many plausible outputs for the same set of inputs.
Open-ended text generation is a complex task to solve and simple prompting techniques won’t give you the results that you are after. Let’s take a look a some of the prompt engineering techniques we’ve used at Flowrite during the past two years, among others.
Zero-shot prompting
The prompt that we created above to extract information from meeting notes is a zero-shot prompt. Zero-shot learning leverages the model's pre-training or instruction fine-tuning to perform tasks without having seen examples of those specific tasks during training.
From our experience in text generation, zero-shot prompts excel at producing varied and creative outputs. However, controlling the format of these outputs or hallucinated content is challenging, especially with smaller LLMs.
A good strategy is to start to engineer a zero-shot prompt and, only if you cannot obtain the desired output, move on to few-shot prompting or mode complex prompt engineering techniques.
Recent models like InstructGPT, GPT-3.5, GPT4, or LLaMa have been aligned to follow instructions by applying reinforcement learning with humans in the loop (RLHF) so zero-shot prompts with relevant context tend to perform incredibly well with these models.
Few-shot prompting
LLMs demonstrate great zero-shot capabilities. However, zero-shot prompts might not be enough for smaller models or models that haven’t been aligned to follow instructions, like the base Davinci model or Cohere’s xlarge generate model.
We’ve found few-shot prompting to be quite effective when we had to work with smaller but faster models. Few-shot prompting enables in-context learning to guide the model toward the desired output.
A simple example of a few-shot prompt for extracting keywords from subject lines can be seen below:
subject: Urgent - bug in production detected
keywords: urgert, bug
--
subject: Board meeting tomorrow - Room 2 at 4pm
keywords: meeting, tomorrow
--
subject: Do you know Flowrite? It will change your life!
keywords: Flowrite, life
--
subject: Architecture review follow-up
keywords: review, follow-up
--
subject: {subject}
keywords:
This is an example of a 4-shot prompt, where we are passing 4 examples of the task at hand to the model.
From our experience, few-shot prompts work reasonably well with smaller models or base models and for tasks that do not need a lot of creativity or diversity of outputs.
We have successfully used this prompting technique to control hallucination, but at a cost of reducing the diversity in the generated outputs. This is an aspect that should consider depending on your application.
Prompt chaining
A more advanced prompting technique that we’ve used at Flowrite is called Prompt Chaining. In simple terms, the output of the prompt becomes the input of the next prompt in the chain.
This technique helps with complex tasks and gives you more control over the LLM, at a cost of higher latencies (more calls to the models) and a potentially higher cost.
If we go back to the zero-shot prompt that we created for extracting bullet points from meeting notes, we could create a prompt that takes the bullet points and produces a document in a specified format. This would be an example of prompt chaining.
It’s also possible to run concurrent calls at a step in the chain if prompts outputs are independent and then aggregate them together as inputs to the next prompt.
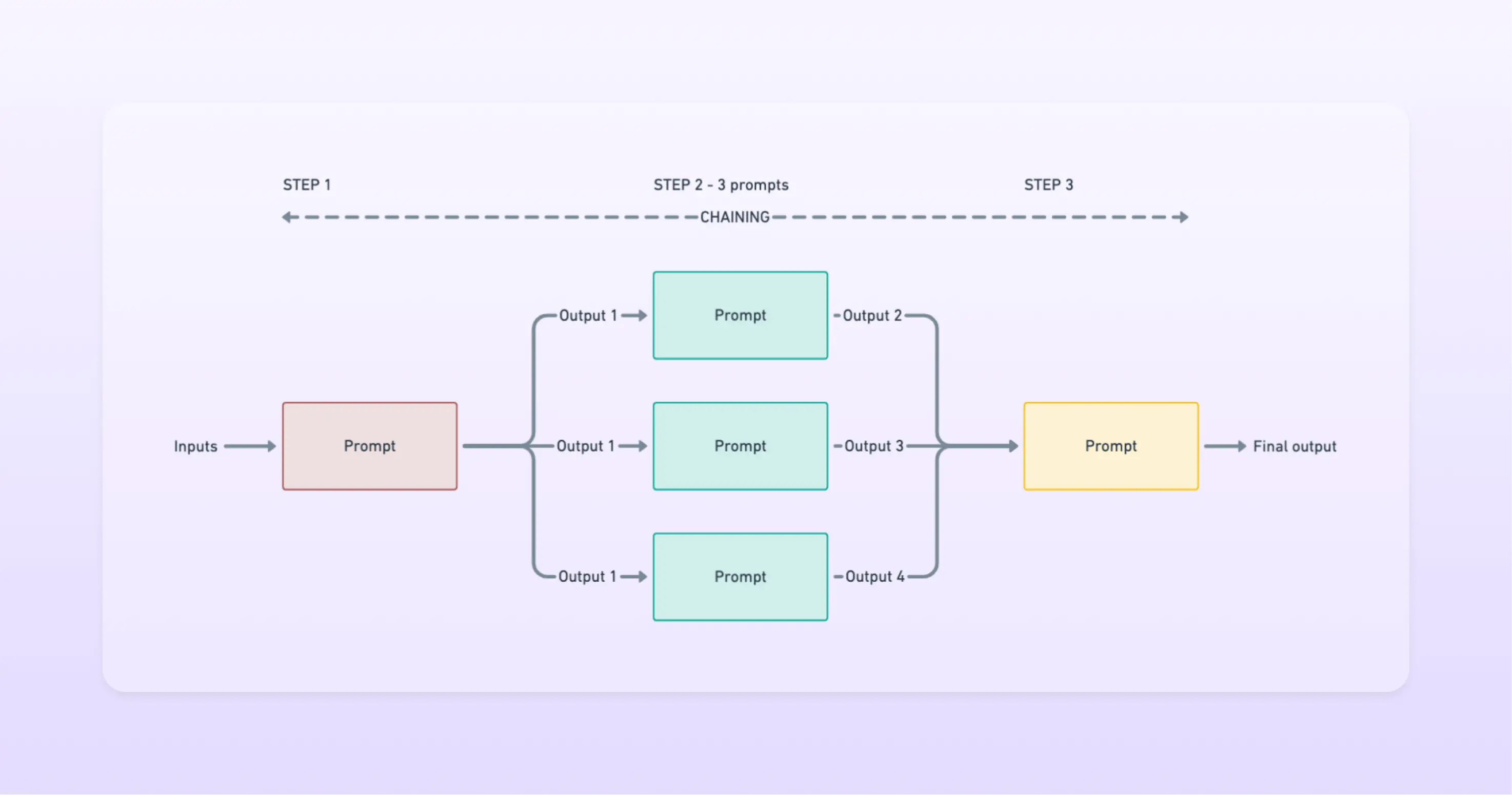
Our two cents if you are building a SaaS product on top of LLMs
Here are some tips that might be valuable if you are getting started with prompt engineering and want to build a product on top of LLMs.
- Use libraries like LangChain to develop your application - When we first started, there were not available libraries like LangChain or platforms like Dust. We had to code everything from scratch. These tools will help you experiment faster, stay organized and deploy your prompts in production.
- Identify your application requirements - More powerful LLMs produce outputs of better quality, but their latencies are higher and are also more expensive. Depending on your application, latency and cost might be more important factors if you can maintain an acceptable level of quality. These are important decisions you have to make before starting to develop a new prompt with a new model.
- Test your prompts extensively and with production data before deploying them - In open-ended text generation, there are no reliable automatic metrics to measure the quality of the generated outputs. An important part of the evaluation process involves human evaluation. Therefore, you might think that you’ve crafted the perfect prompt until you share it with your teammates or test it on a significant amount of production data. We as developers are biased and have a good understanding of how these models work. This might lead to a flawed evaluation. Always run internal tests with other teams in your company and also run online evaluations by fetching production data and evaluating the outputs. You’ll be surprised by how many unexpected behaviors you can find by doing this.
- Collect user feedback on the outputs of your models - As there are no reliable metrics for text generation, user feedback is one of the most valuable metrics that can tell how your model is doing. You can use this feedback to compare models or prompt by running A/B testing experiments.
- When a new model is released, rework will be needed - A prompt that works really well with text-davinci-003, might not perform well with GPT-3.5-turbo. Actually, this is what our experience tells us. Expect some rework to be done in terms of prompt engineering or hyper-parameter tuning if you want to switch to a different model, even if it is newer or more powerful.
Read more
Our team has been experimenting with multiple LLMs since 2020. If you want to read more lessons we’ve learned building Flowrite, find our other blog posts on technological topics here.


