
Introduction
Large language models are increasingly expected to handle massive inputs—such as entire books or all customer interactions of a company. However, scaling context windows to millions of tokens leads to soaring computational costs and memory constraints, often increasing quadratically.
This post explores two training-free innovations—Infinite Retrieval and Cascading KV Cache—which rethink how LLMs process vast inputs.
Both methods build on sliding window attention, processing text in overlapping chunks, but introduce novel strategies to retain critical information without storing everything.
By the end of this post, you'll understand how these methods optimize memory use, prioritize critical information, and enable scalable solutions for tasks ranging from legal document analysis to sustained customer support interactions.
Infinite Retrieval: Precision in Token Selection
Developed by Xiaoju Ye et al., Infinite Retrieval leverages the large language model's (LLM) attention mechanism to identify and retain the most critical tokens from an effectively "infinite" input sequence.
How Infinite Retrieval Works
Infinite Retrieval helps language models process very long inputs by breaking them into smaller parts and keeping only the most important information as it goes.
-
Chunking: The input is split into smaller documents, each made up of complete sentences. The Chunk Size parameter sets a target number of tokens per document, but the actual size may vary slightly to avoid cutting sentences in half [1].
-
Attention-Driven Selection: The model works through each document one by one. For each document, it combines the current document with tokens saved from earlier documents. Using attention scores, it picks the top-K tokens (e.g., the 300 most relevant ones) from the current document based on their importance to the query, then selects the full sentences containing those tokens.
-
Token ID Caching: Instead of saving full key-value (KV) states, the method stores the token IDs of the entire sentences that have the top-K tokens. This keeps the context around those tokens intact. These saved sentences are then merged with the next document to form a MergeToken sequence, which the language model processes in the next step.
Why Infinite Retrieval Works
1. Memory Efficiency
The method reduces memory demands by caching only token IDs rather than the memory-intensive full KV states used in traditional approaches like StreamingLLM (Xiao et al., 2023). This design choice eliminates the need to store high-dimensional KV representations outside the model.
For example, in the NarrativeQA task, it retains just 4.5% of the original input tokens (reducing 18,409 tokens to 834). Similarly, in HotpotQA, it keeps only 8.7% of the tokens (9,151 reduced to 795). This token reduction allows the model to handle long contexts efficiently without overwhelming memory resources, enabling scalability to larger inputs. [2,3]
2. Task Focus
Infinite Retrieval excels in precision-oriented tasks because it uses the LLM's attention mechanism to pinpoint tokens most relevant to the query. The final-layer attention scores effectively identify regions in the input that contain answers. This selective retention ensures that critical information is preserved across chunks, even in multi-document scenarios.
For instance, in HotpotQA, a multi-document QA task, the method achieves a performance improvement of 288% (from 14.8 to 57.52) by focusing on query-specific details. This makes it particularly effective for tasks requiring high precision, such as QA over legal documents or identifying error codes, where only a small subset of the input is relevant. [4,5,6]
Example – Customer service
Consider a customer service bot processing a 10,000-token support ticket.Infinite Retrieval can isolate key details—like account numbers or error messages—retaining only a fraction of the input (e.g., 8.7%, as demonstrated in HotpotQA) while maintaining accuracy.
This efficiency ensures precise API calls without the overhead of storing unnecessary data, directly reflecting the method's strengths. [7,8]
Cascading KV Cache: Layered Memory Management
Proposed by Jeffrey Willette et al., this method extends sliding window attention by maintaining a tiered KV cache where tokens are retained based on their historical importance.
How Cascading KV Cache Works
-
Sub-Cache Layers: Tokens are stored across multiple sub-caches, with each successive sub-cache accepting a fraction of tokens evicted from the previous one (e.g., every 2nd token if halved). This creates a cascading structure where deeper layers hold older, selectively retained tokens.
-
EMA-Driven Retention: An exponential moving average (EMA) of attention scores tracks each token's historical importance, prioritizing retention of tokens with consistently high relevance over time.
-
Dynamic Balancing: Recent tokens populate the top layer for immediate context, while older tokens with high attention scores filter into deeper layers, extending the effective context window.
Why Cascading KV Cache Works
1. Extended Context Memory
By organizing the KV cache into cascading sub-caches, the method retains critical tokens longer than traditional sliding window approaches.
The paper demonstrates this through attention matrix visualizations, showing preserved context beyond static limits, with a total token span approximated as follows:
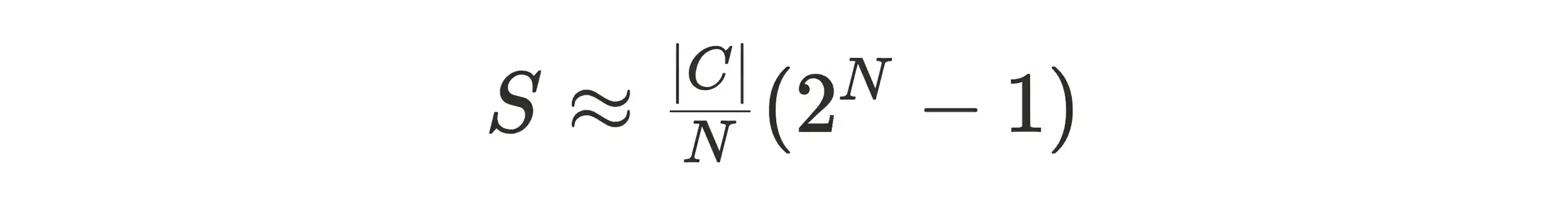
2. Performance Gains
The method excels in long-context tasks, achieving:
- A 12.13% average improvement in LongBench benchmarks.
- A 4.48% boost in book summarization ROUGE scores over the best linear baseline.
- Superior passkey retrieval accuracy at 1M tokens, maintaining better-than-random performance (10%) after four doublings of a 65K cache size (24 percentage points higher than Streaming LLM at 1M tokens; . [11, 12,13]
3. Efficiency
It reduces prefill stage latency by a factor of 6.8 compared to Flash Attention 2 on 1M tokens, taking only 14.8% of the quadratic method's time, making it ideal for real-time applications. [14]
Example – Healthcare copilot
A healthcare copilot could use Cascading KV Cache to track patient history across a 50-page medical record (approximately 10,000–12,500 tokens at 200–250 tokens per page).
This approach would ensure that treatments align with earlier diagnoses while maintaining low latency for real-time interactions.
┌───────────────────────┐
│ New Tokens │
│ (Recent Input) │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ Sub-Cache 1 │
│ (Recent Context) │
│ [● ○ ● ○ ● ○] │ // ● = High Attention, ○ = Low Attention
└───────────┬───────────┘
│
│ Evicted Tokens
│ (Lowest EMA)
▼
┌───────────────────────┐
│ Sub-Cache 2 │
│ (Mid-tier Context) │
│ [● ● ○ ● ● ○] │
└───────────┬───────────┘
│
│ Evicted Tokens
│ (Lowest EMA)
▼
┌───────────────────────┐
│ Sub-Cache 3 │
│ (Oldest Important) │
│ [● ● ● ● ● ○] │
└───────────┬───────────┘
│
│ Discarded Tokens
│ (Lowest EMA)
▼
┌───────────────────────┐
│ Discarded │
│ [○ ○ ○ ○ ○ ○ ] │
└───────────────────────┘
┌─ Note ───────────────────────────────────────────────┐
│ Tokens are retained across sub-caches based on their │
│ historical importance (EMA of attention scores). │
│ Deeper layers hold older, high-relevance tokens, │
│ extending the effective context window: │
│ S ≈ (|C| / N) * (2^N - 1) │
└──────────────────────────────────────────────────────┘
Comparison: Key Tradeoffs and Metrics
| Feature | Infinite Retrieval | Cascading KV Cache |
|---|---|---|
| Memory Use | Caches only token IDs, ultra-lean | Uses tiered KV sub-caches, moderate memory |
| Best Use Case | QA over very long documents (e.g., legal or support tickets) | Long-context tasks (e.g., summarization or medical records) |
| Key Advantage | High precision in token selection | Extended context memory |
| Notable Metric | 288% performance improvement in HotpotQA | 6.8x faster prefill, 12.13% improvement in LongBench |
| Limitation | Less suited for tasks needing broad context (e.g., summarization) | May require tuning of sub-cache parameters |
Extending Context Horizons
While Infinite Retrieval and Cascading KV Cache emphasize selective retention within fixed limits, this isn't the only way to enhance a model's long-context performance.
In contrast, YaRN and LongRope—two fundamental RoPE methods—re-engineer the architecture to natively handle extended contexts. They excel in tasks requiring end-to-end coherence, such as document-wide QA or essay writing.
Both methods enhance Rotary Position Embeddings (RoPE), the essential positional encoding layer for sequence modeling:
YaRN (Yet another RoPE ExtensioN method)
YaRN applies a nuanced scaling strategy to extend LLM sequence processing. It adjusts RoPE dimensions based on frequency:
- High-frequency dimensions (smaller indices) receive no interpolation, meaning they have a scaling factor of
1. - Low-frequency dimensions (larger indices) are fully interpolated based on the extension ratio
s, resulting in a scaling factor of1/s. - For dimensions in between, the scaling factor increases linearly from
1/sto1, creating a smooth transition across these ranges. [15,16,17]
In simple terms, YaRN keeps short-range details sharp by leaving some dimensions unchanged, while it stretches others to manage longer sequences, blending the two approaches in the middle for balance.
For example, YaRN is used with QwQ to target a 128k-token context window. However, extending the context window with YaRN can noticeably reduce short-task accuracy. Without proper settings, QwQ may even loop in circular reasoning without reaching a final answer.
LongRope
LongRope employs a PPL-guided evolutionary search to optimize RoPE scaling factors for lengthy sequences, enabling effective handling of long contexts.
While specific accuracy figures vary, LongRope demonstrates strong performance on long-context benchmarks like RULER and Needle-in-a-Haystack when enhanced to LongRoPE2. [18,19,20]
Example Applications
| Historian | Legal analyst |
|---|---|
| Could leverage LongRope to summarize lengthy historical texts (e.g., 100,000 tokens) fluidly, bypassing text chunking, though performance may vary depending on the method's configuration. | Might use YaRN to review long contracts in a single pass, but should be aware of potential performance degradation on very long contexts or short-task accuracy. |
Why YaRN and LongRope Matter
Unlike retrieval-based methods bound by fixed limits, YaRN and LongRope aim to embed long-context support directly into the architecture, favoring holistic coherence over selective focus.
However, both methods come with trade-offs: YaRN struggles with performance beyond certain lengths and on short tasks, while LongRope's effectiveness is enhanced in its successor, LongRoPE2, which mitigates some of these issues.
Despite these limitations, they remain valuable for tasks requiring seamless understanding, such as legal analysis or historical document synthesis, especially when using optimized versions like LongRoPE2.
Future Outlook
We have explored methods for both context retention as well as extending context by leveraging techniques around embeddings.
Infinite Retrieval and Cascading KV Cache push LLMs closer to human-like context handling—one zeroing in on key details, the other weaving a broader memory tapestry. They sidestep the memory crunch without retraining, promising AI that can nail a question from a 1M-token doc or chat coherently for hours.
For the AI field, they hint at a future where models prioritize and manage context smarter, not just bigger.
Reading Companion
Infinite Retrieval: Attention Enhanced LLMs in Long-Context Processing
X. Ye, Z. Wang, and J. Wang, Feb. 18, 2025, arXiv: arXiv:2502.12962. doi: 10.48550/arXiv.2502.12962.
- 1 Appendix A (p. 16): Chunk Size set to 1024 tokens. Specifies the chunking parameter in implementation details.
- 2 StreamingLLM (Xiao et al., 2023): Retains tokens via KV caches. Highlights StreamingLLM's use of KV states for retention.
- 3 Table 4 (p. 12): Reduces tokens, e.g., 18,409 to 834. Shows token reduction stats, like NarrativeQA example.
- 4 Section 3 (p. 4): Attention scores locate answers. Explains how attention identifies query-relevant regions.
- 5 Figure 2c (p. 4): Visualizes attention on answer regions. Depicts last-layer attention heatmap for QA sample.
- 6 Table 1 (p. 8): Shows score improvement to 57.52. Lists HotpotQA performance gain (14.8 to 57.52).
- 7 Table 4 (p. 12): Reduces HotpotQA to 995 tokens. Demonstrates token reduction for HotpotQA task.
- 8 Section 5.2 (p. 8): Details performance improvements. Reports enhanced QA results across LongBench tasks.
Training-Free Exponential Context Extension via Cascading KV Cache
J. Willette, H. Lee, Y. Lee, M. Jeon, and S. J. Hwang, Feb. 28, 2025, arXiv: arXiv:2406.17808. doi: 10.48550/arXiv.2406.17808.
- 9 Figure 1 (p. 1, Section 1) compares attention matrices of Streaming LLM and Cascading KV Cache, showing preserved context. Figure 10 (p. 9, Section 4.6) visualizes how cascades extend token retention.
- 10 Equation 4 (p. 6, Section 3.1) mathematically defines the extended context length achieved by cascading sub-caches.
- 11 Page 7 (Section 4.2, 4.3) details PG19 perplexity (0.4%) and Booksum ROUGE (4.48%) improvements. Page 10 (Section 6) summarizes these with LongBench (12.13%) gains.
- 12 Page 8 (Section 4.4) reports 24pp higher passkey retrieval accuracy at 1M tokens. Page 10 (Section 6) confirms this performance edge.
- 13 Page 2 (Section 1) introduces passkey retrieval superiority. Page 8 (Section 4.4) and Figure 8 detail and visualize accuracy at 1M tokens.
- 14 Page 1 (Abstract) claims 6.8x latency reduction. Page 6 (Section 4.1) details implementation efficiency. Page 10 (Section 6) summarizes this benefit.
YaRN: Efficient Context Window Extension of Large Language Models
B. Peng, J. Quesnelle, H. Fan, and E. Shippole, Nov. 01, 2023, arXiv: arXiv:2309.00071. doi: 10.48550/arXiv.2309.00071.
- 15 Section 3.2 (p. 6): Details the "NTK-by-parts" interpolation, the core of YaRN's scaling strategy.
- 16 Definition 2 (p. 6): Provides the mathematical formulation of the piecewise scaling.
- 17 Section 3.4 (p. 7): Defines YaRN as using "NTK-by-parts," linking it to the strategy.
LongRoPE2: Near-Lossless LLM Context Window Scaling
N. Shang et al., Feb. 27, 2025, arXiv: arXiv:2502.20082. doi: 10.48550/arXiv.2502.20082.
- 18 Section 3.1 (p. 4): Hypothesis on higher-dimension training insufficiency. Proposes insufficient training causes OOD issues.
- 19 Section 3.2 (p. 5): Evolutionary search with needle-driven rescaling. Describes RoPE rescaling via evolutionary algorithm.
- 20 Section 3.3 (p. 6): Mixed training preserves short-context accuracy. Outlines training to maintain short-context performance.


