
Introduction: From LLM Evaluations to AI Agents
Evaluating large language models (LLMs) has become a lot more involved over the years. Early approaches have relied on simple scoring metrics or "vibe checks," while newer techniques—such as "LLM-as-a-judge"—dive deeper into a model's behavior. But with AI agents now managing multi-step conversations and external tool integrations, the task of building robust evaluation datasets has gotten a whole lot tougher. Scripting realistic user interactions, anticipating edge cases, and incorporating adversarial elements can be both time-consuming and expensive.
At Flow AI, we've been paying close attention to this shift toward agent-oriented evaluations. Recently, we examined Salesforce's APIGen approach and how standardized JSON, combined with function-call generation and verification, enhances the reliability of function-calling datasets.
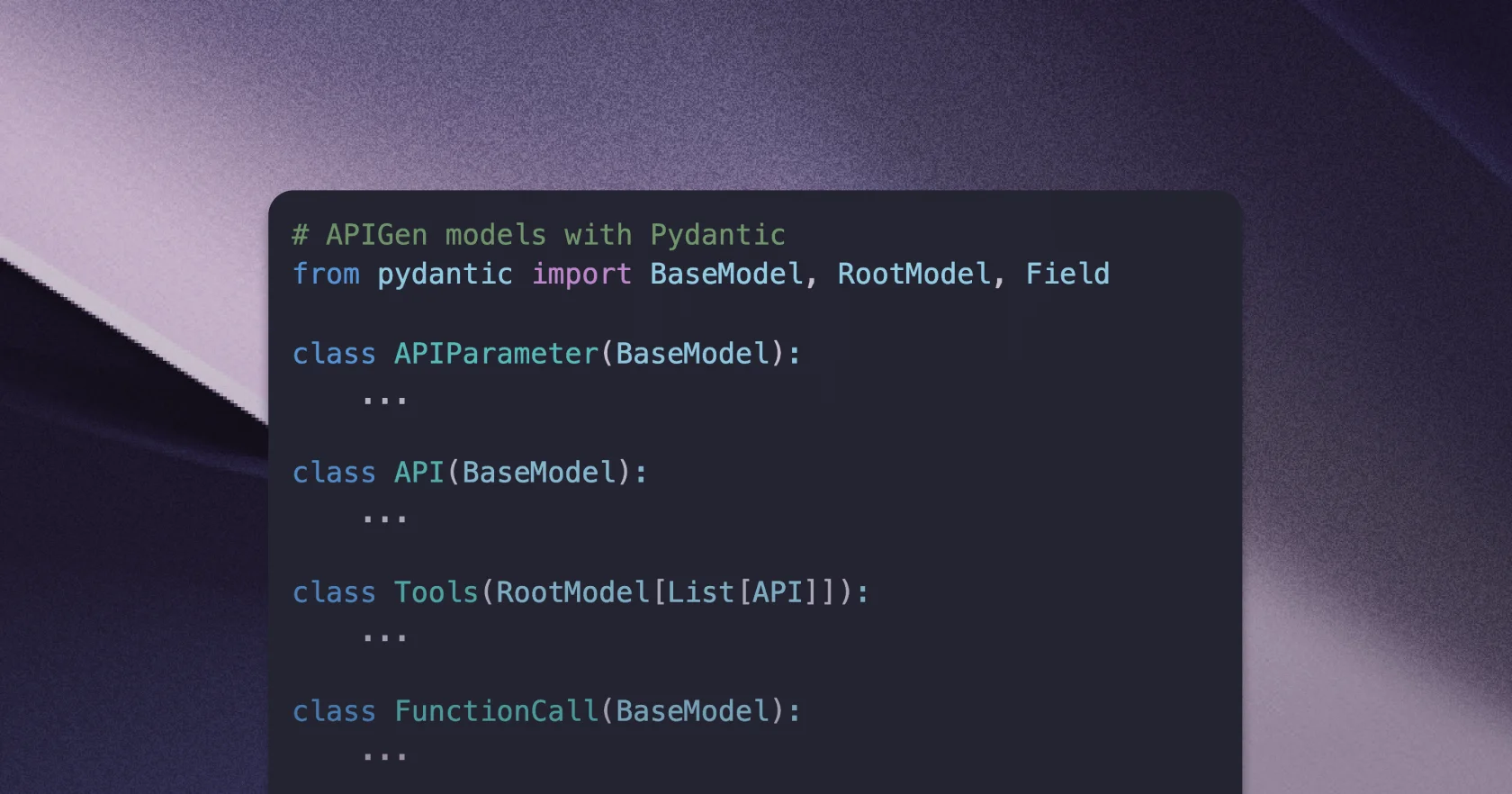
Blueprint for tool-augmented LLMs: Learning from Salesforce's APIGen approach
We explore how standard JSON, combined with function-call generation and verification, helps AI engineers build more reliable, verifiable, and varied function-calling datasets.
Building on that, we also came across this great piece of research from Zendesk that offers a streamlined way to automate test set creation for conversational AI agents in the customer support domain.
In this post, we'll walk through an example from the Auto-ALMITA dataset, demonstrating how a test case is constructed step by step—from defining structured procedures to extracting granular test scenarios for evaluation. This example represents the outcome of Zendesk's pipeline, showing how AI agent behaviors can be systematically tested against real-world conditions.
By the end of this post, you'll see how automated test generation improves AI agent evaluation, enabling scalable, high-coverage testing while ensuring AI models perform consistently and reliably across diverse scenarios.
Why Comprehensive Evaluation Datasets Matter
As we move from testing simple input-output pairs to evaluating full-fledged conversational AI agents, the demands on our datasets increase dramatically. Traditional datasets focusing on isolated questions simply can't capture the complexity of multi-step interactions or the unpredictable ways users might deviate from a script. If you're building an AI agent for customer support, you'll recognize some specific challenges:
- Multi-Turn Complexity – Can the agent maintain context over several exchanges, keep track of details (such as order IDs), and still produce coherent responses?
- Tool Integration – Does the agent accurately select the right tool and perform a correct API call (e.g., cancel an order, process a refund) without mixing up parameters or inventing information that isn't in its workflow?
- Realistic Scenarios – Is the agent robust against adversarial or off-topic messages, and does it adhere to the right process even when users behave unpredictably?
Zendesk's Automated Test Generation Pipeline
Zendesk's research presents a structured approach to automating the evaluation of AI agents by systematically generating realistic test cases. Their pipeline consists of multiple steps, each designed to ensure that AI responses and actions align with expected behavior across different user interactions.
Instead of manually crafting test cases, Zendesk's method generates:
| Step | Description |
|---|---|
| Structured Procedures | Defines how an agent handles specific customer intents. |
| Flowgraphs and Conversation Graphs | Maps the AI agent's decision-making steps and models real multi-turn interactions. |
| Noise Variations | Introduces out-of-procedure and attack messages into the conversations. |
| Path Sampling | Ensures diverse conversation flows by selecting different paths through the conversation graph using a weighted random walk algorithm. |
| Conversation Generation | Synthesizes realistic multi-turn dialogues based on the sampled paths while following structured constraints. |
| Test Extraction | Breaks down conversations into measurable test cases for evaluation. |
| Automated Validation | Removes redundant or incomplete tests, ensuring high dataset quality. |
This automated process allows for scalable, high-coverage AI agent evaluation without the overhead of manual dataset creation.
Example Walkthrough: From Intent to Test Cases
To see how this approach works in practice, let's follow an example from the Auto-ALMITA dataset, for a test case where a user reports a problem with their internet connection.
Test Scenario: A customer contacts support because their wifi router isn't working. The AI agent must diagnose the issue and either resolve it or escalate.
How the Example Moves Through the Pipeline:
1. From Intents to Procedures
The intent "My router isn't working." is identified, and a structured troubleshooting procedure is created. The AI follows steps like asking for the customer's account number, checking if they've restarted their router, retrieving customer details, and either providing a fix or escalating the issue.
# Generated Procedure
1. Greet the customer politely and ask for their name and account number.
2. Tell them that you understand their issue is related to their router or modem not working.
3. Ask the customer if they have performed basic troubleshooting steps such as restarting their device and/or modem.
- If they have performed the basic troubleshooting and the problem persists, proceed to the next step.
- If not, guide the customer to shut down their device and restart the modem. If the problem is resolved, close the conversation. If not, proceed to the next step.
4. Request to know more details about the problem: Is there any error message? Are the lights on the modem or router not behaving normally? Is the issue affecting all devices or only some?
5. Based on the customer's response:
- If there's an error message, look up the error in the system's troubleshooting manual and provide the displayed solution.
- If the issue is with the lights on the router, guide the customer to reset the router using the reset button on the device.
- If the issue is affecting only some devices, guide the customer to forget the network on the affected devices and reconnect.
6. If the previous steps did not resolve the issue, escalate the issue to level II support. Provide the customer with the estimated wait time and assure them that they will be contacted as soon as possible. Thank the customer for their patience and close the conversation.
2. Graph-based represenations
To ensure structured, logical AI behavior, the system converts procedures into two key representations:
- Flowgraph – A directed graph capturing the AI agent's decision-making process. Each node represents an agent action, including messages, API calls, and interaction endpoints, while edges represent user responses or API outputs. This ensures all procedural steps are followed systematically.
- Conversation Graph – A structured representation that transforms the flowgraph into a realistic dialogue, mapping out user and agent interactions in a multi-turn format. Customer messages, agent responses, and API calls are distinct node types, creating a natural flow of conversation.
These intermediate representations are crucial because they provide a structured way to explore different conversational paths, ensuring that troubleshooting steps, edge cases, and escalations are accounted for. By representing conversations as graphs, the system reduces hallucinations, enforces logical consistency, and enables scalable, automated test generation.
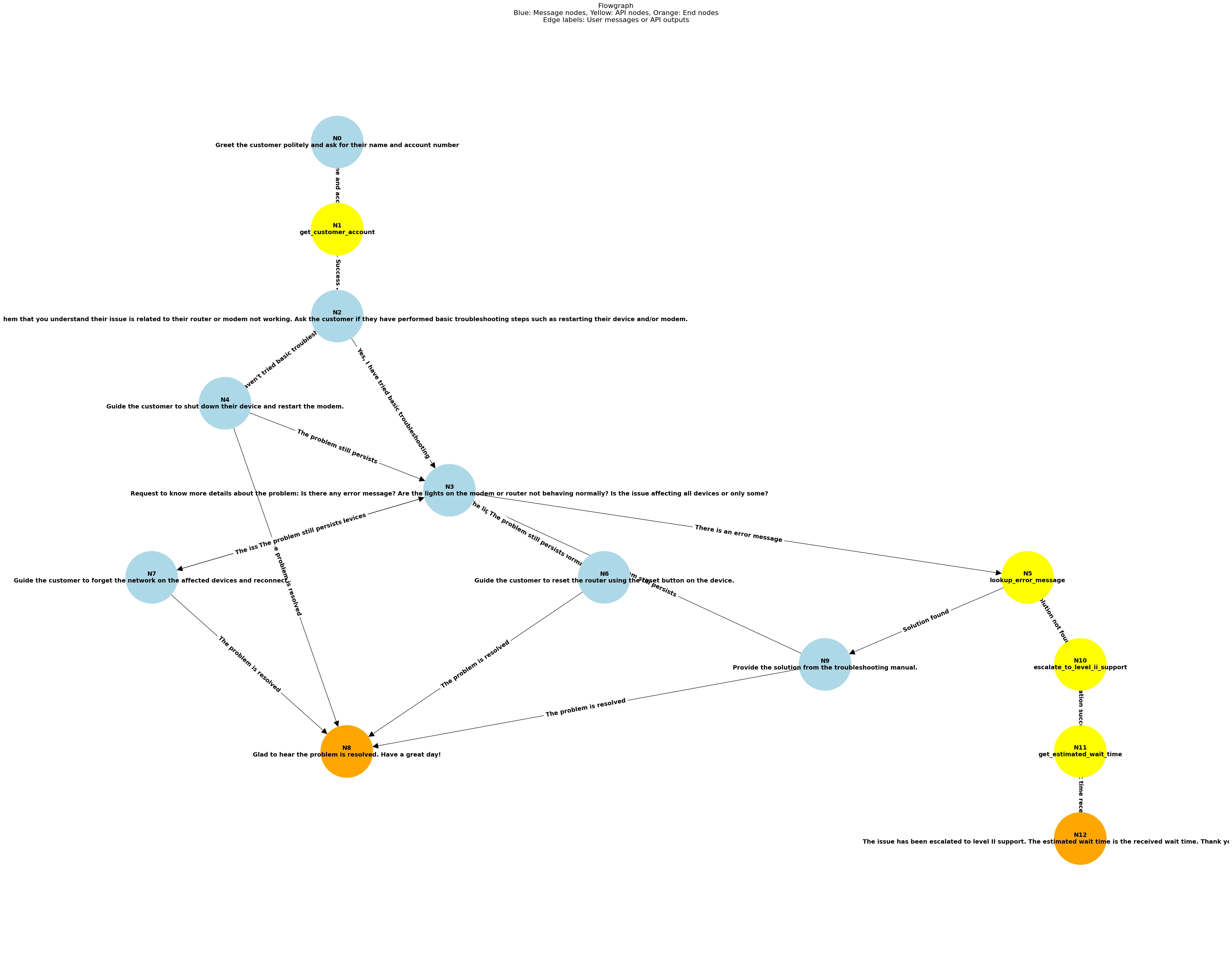
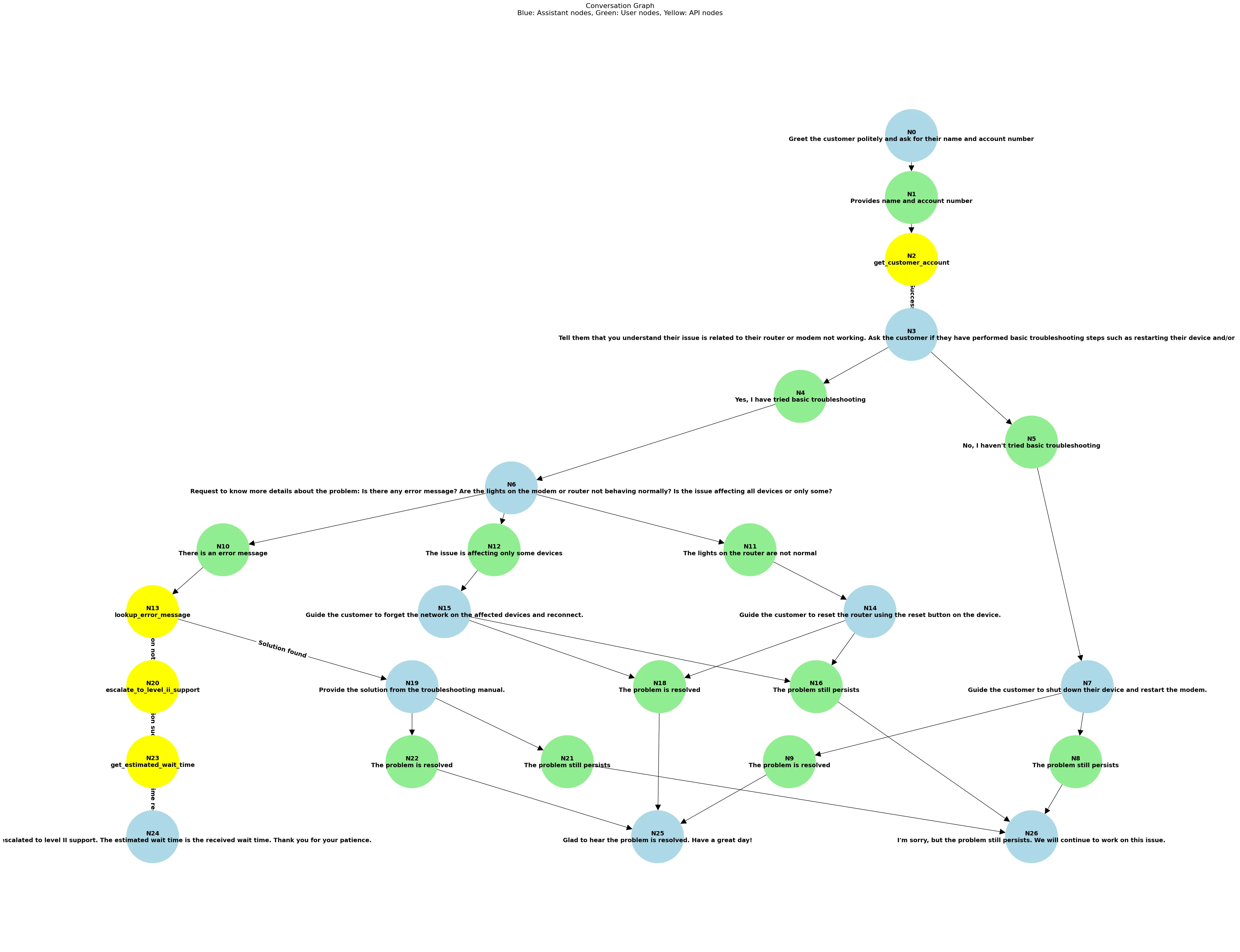
3. Noise Generation
The system injects unexpected user messages into the conversation graph to simulate real-world deviations. These messages include:
- Out-of-procedure inputs – Unrelated user messages (e.g., asking about billing during troubleshooting).
- Attack messages – Adversarial inputs designed to disrupt the conversation.
To keep interactions structured, the agent responds with a predefined redirection (e.g., "I'm here to help with troubleshooting your wifi connection"). This tests the AI's ability to handle unpredictable behavior while maintaining focus on the intended task.
4. Path Sampling and Conversation Generation
- Path Sampling: The system selects conversation paths using a modified weighted random walk algorithm that improves nodes coverage.
- Example: The AI agent may encounter cases where the user reports an issue, provides account details, and undergoes multiple troubleshooting steps before escalating to support.
- Conversation Generation: Once a path is chosen, an LLM synthesizes the full conversation while following key constraints:
- Every API call is followed by its expected output (e.g., retrieving customer data before troubleshooting).
- User and assistant turns alternate, ensuring realistic multi-turn dialogue.
- The assistant's responses are strictly grounded in API results and procedural rules.
5. Test Extraction: Breaking Down the Conversation
After generating a conversation, the system splits it into smaller test cases, each ending in either:
- A customer message (e.g., "I have an error message")
- An API output (e.g., "Reset network settings")
Each test case consists of:
- Context (previous messages leading up to the test point).
- Expected output (the AI's next correct action).
This allows precise evaluation by checking if the AI follows the correct sequence of steps at each stage of troubleshooting.
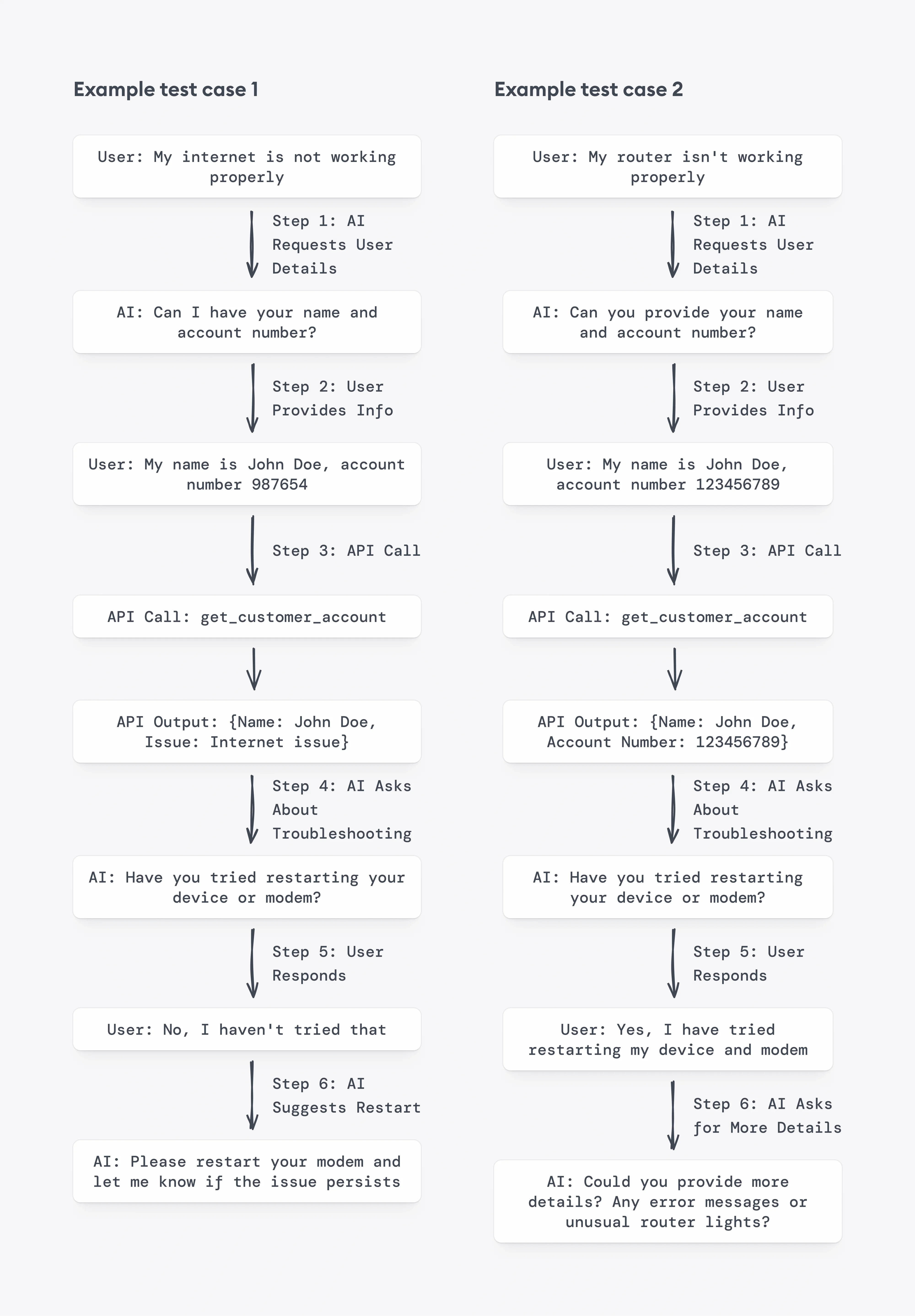
Evaluation Metrics for the Test Cases
With the generated test cases from the Auto-ALMITA dataset, we can measure an AI agent's performance across multiple dimensions to ensure it follows the expected conversational flow while handling tool usage correctly. The dataset enables evaluation across the following key metrics:
| Metric | Description |
|---|---|
| Reply Recall | Does the AI correctly recognize when it should reply instead of making an unnecessary API call? |
| Correct Reply | When replying, does the AI's response closely match the expected output? (Measured using BERTScore with a similarity threshold of 0.55.) |
| API Recall | When the correct action is to call an API, does the AI correctly detect that an API call is needed instead of responding with a message? |
| Correct API Call | When making an API call, does the AI select the correct function (e.g., lookup_error_message when an error code is detected)? |
| Correct API Parameters | When making an API call, does the AI pass the correct parameters (e.g., the correct account number or error message)? |
| Test Accuracy (Test Correctness) | Does the AI produce the correct response or API call in a single test case? |
| Conversation Accuracy (Conversation Correctness) | Across an entire conversation, does the AI pass all test cases in sequence without making errors? |
Conclusion
Through our walkthrough of an example from the Auto-ALMITA dataset, we've seen how Zendesk's automated test generation pipeline systematically constructs evaluation datasets—from defining structured procedures to extracting granular test cases. This approach eliminates much of the manual effort traditionally required while ensuring AI agents are tested against diverse, real-world conditions.
By automating test set creation, this method scales AI evaluation, improves coverage, and ensures consistent benchmarking. The ability to inject variability through noise generation and explore rare conversational paths via path sampling makes it especially valuable for assessing how well AI agents handle both typical and edge-case interactions.
While originally designed for customer support AI, this structured test generation approach can be adapted to other domains where AI must follow defined workflows—such as healthcare assistants, financial advisory bots, or legal AI tools. Any system that interacts with external tools, retrieves structured information, or manages multi-turn user interactions could benefit from a similar automated evaluation framework.
Sources
- Original research paper: Automated test generation to evaluate tool-augmented LLMs as conversational AI agents
- Github repo: ALMITA-dataset


