
Introduction
As the field of deep learning (DL) and natural language processing (NLP) continues to evolve at an unprecedented pace, large language models (LLMs) have become increasingly popular due to their impressive benchmark-breaking performance on a wide range of NLP tasks. Such language models are no longer only the object of academic research but their success has also led to their commoditization & use in real-world scenarios, with several pre-trained models now available to developers for general use.
LLM fine-tuning is a technique in natural language processing (NLP) that involves adapting a pre-trained LLM to a specific task by fine-tuning it on a task-specific dataset.
While pre-trained LLMs offer a valuable starting point for many NLP tasks, fine-tuning them over task-specific datasets has emerged as a crucial tool for improving their performance and bolstering defensibility. Fine-tuning allows developers to adapt a pre-trained model to a specific task by training it on a domain-specific dataset, thus tailoring the model's language understanding to the specific needs of the task.
One of the most significant advantages of this approach is its ability to enhance the performance of smaller language models (LLMs with lesser number of parameters), enabling them to match or even surpass the performance of similar LLMs with a higher number of parameters. It is also massively helpful for AI alignment and reducing hallucination/confabulation.
By fine-tuning such a smaller language model over a task-specific dataset, developers can tailor the model's language understanding to the specific requirements of that task. This allows the model to focus on the most relevant features of the task, reducing noise and improving accuracy. Additionally, fine-tuning enables the model to learn from the task-specific dataset, further improving its performance on that particular task.
From a product-centric perspective, one of the most significant benefits is the reduction of latency, which results in enhanced user experiences and less wait time for users.
From a business-centric perspective, the cost savings associated with fine-tuning language models over task-specific datasets are substantial. By fine-tuning an existing pre-trained language model to a specific task, businesses can significantly reduce the amount of money spent per token at inference time.
Dataset Preparation Pipeline for Flowrite
Finetuning Problem Structure
Our goal at Flowrite with Finetuning is to provide the AI language model with a deep understanding of the relationship between inputs and outputs in email/message generations.
Our team recognized that to fine-tune the LLM to generate appropriate outputs based on different types of inputs, we needed a comprehensive dataset consisting of email samples. This dataset would serve as the foundation for fine-tuning the LLM, enabling it to better understand the nuances and complexities of email generation.
For early experiments with fine-tuning, we decided to leverage production database that houses the generation data from the product usage.
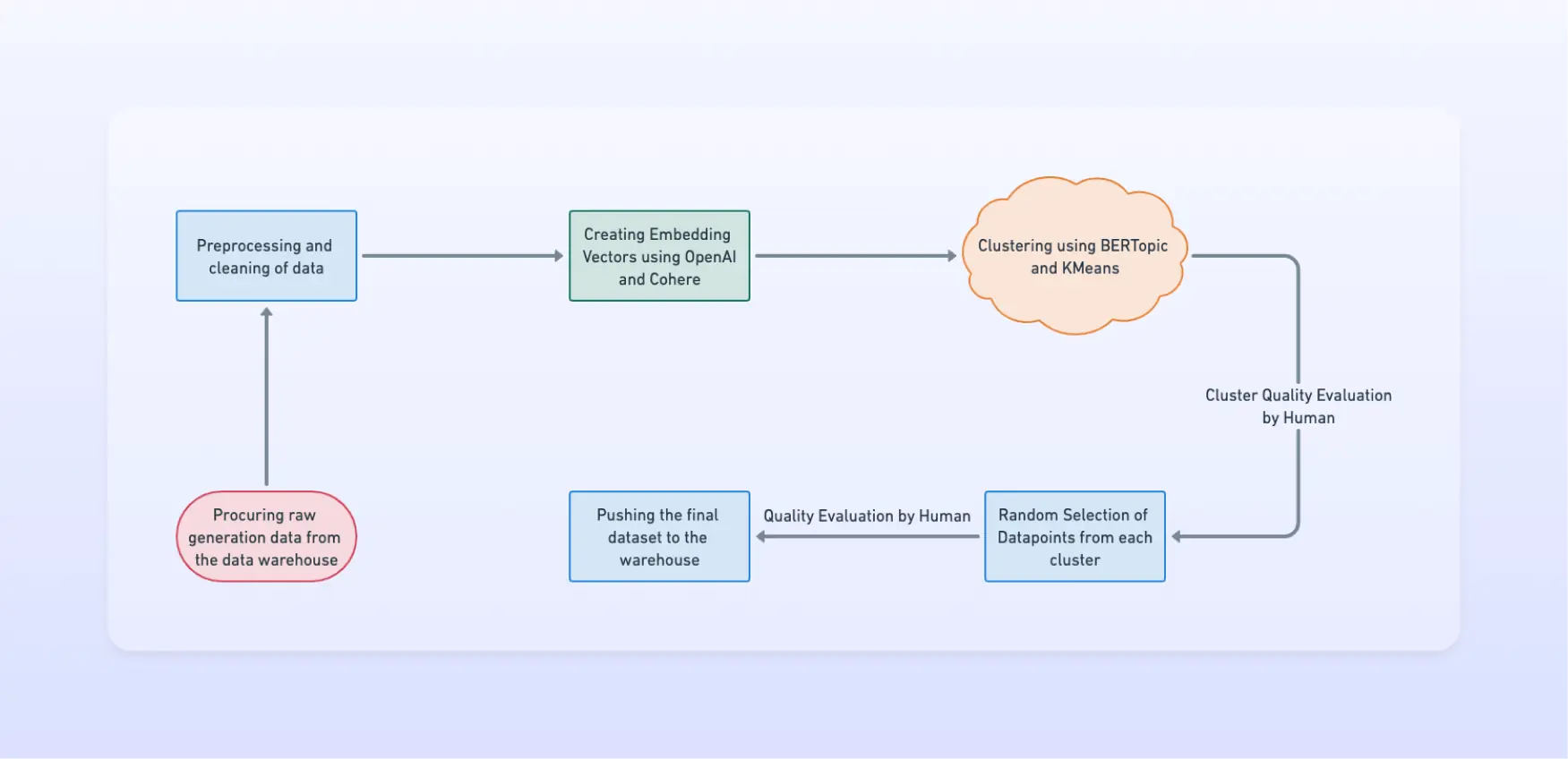
Planning Dataset Structure
Then we set out to plan the desirable attributes of of the final dataset and converged on the following:
1. Data Diversity: To ensure that our fine-tuned model can produce high-quality emails and messages in response to diverse inputs, it was essential to have a dataset that encompasses a broad range of real-world topics that our Flowrite users typically encounter. Therefore, we decided to include email generations that cover all kinds of scenarios, allowing our model to learn how to generate appropriate outputs for various types of inputs.
2. Data Distribution: In order to ensure that our data is diverse, we had to select data points from our production data that provide a balanced representation of all possible use cases. To achieve this, we have devised a suitable categorisation plan:
- 50% General Template Data (GT) : Our General Template is used for a variety of use cases, having substantial GT data ensured a good distribution.
- 50% Data from Templates specific generators : Our template specific generators are attuned to perform well on specific template cases like candidate rejection, inbound sales proposal acceptance, meeting scheduling, etc. This has always helped in ensuring highest quality generations in terms of content and structure with minimal stochasticity.
3. Dataset Size: We decided on a datapoint size of 700-800 datapoints for the phase 1 as we did not want it to run for too long and wanted to rake in the learnings rapidly.
4. Dataset Quality: We converged on the following boundary conditions to ensure dataset quality.
- Fixing timeline: For General Template generations, our latest implementations (cognitive architecture based prompt and codename AITv3) have been more robust in terms of their contextual awareness, content and structure. This gave us the confidence to blatantly prioritise their generations over earlier General Template generations.
- Focus on High Quality Data: As a product centric company, we want to ensure that our AI models are aligned with the preferences of our users, while also generating high-quality content that demonstrates strong contextual awareness, content, and structure. Therefore, we have decided to prioritize the generation data that is high-quality and also correlates positively with our product usage metrics and retention rates.
- Including Human Evaluation: This was an additional check to ensure that the generation data from both our General Template and template specific generators is contextually aware and relevant to set of input given by users in the form of instructions. For example, we did not want very good generations in the dataset if they had a lot of hallucinated content and were in contradiction to information given to them via inputs.
Data Sourcing and Preprocessing of Data
Our data team has worked rigorously to build the underlying infrastructure that makes working with data super convenient for the AI team. Our data warehouse is hosted on Snowflake's platform and is integrated with our cloud notebook of choice, Deepnote. This makes it extremely easy for AI engineers to source data from the warehouse using SQL queries inside Deepnote and start manipulating it using Pandas.
Due to the high-dimensional embedding vector offerings from LLM providers like Cohere and OpenAI, the contextual capturing of text in the vector space has become world-class. In our opinion, this has largely eliminated the need for traditional NLP preprocessing techniques such as tokenization, lowercasing, stop-word removal, and stemming, among others.
However, as an AI product company, it is significant to be cautious and weed out the noisy user input data that could adversely affect the quality of the dataset for fine-tuning. For Flowrite, the two biggest sources of such input data points are identity settings and instructions for generations (images below).Most of the preprocessing involved using rule-based NLP systems to eliminate such noisy user input data points from the dataset.
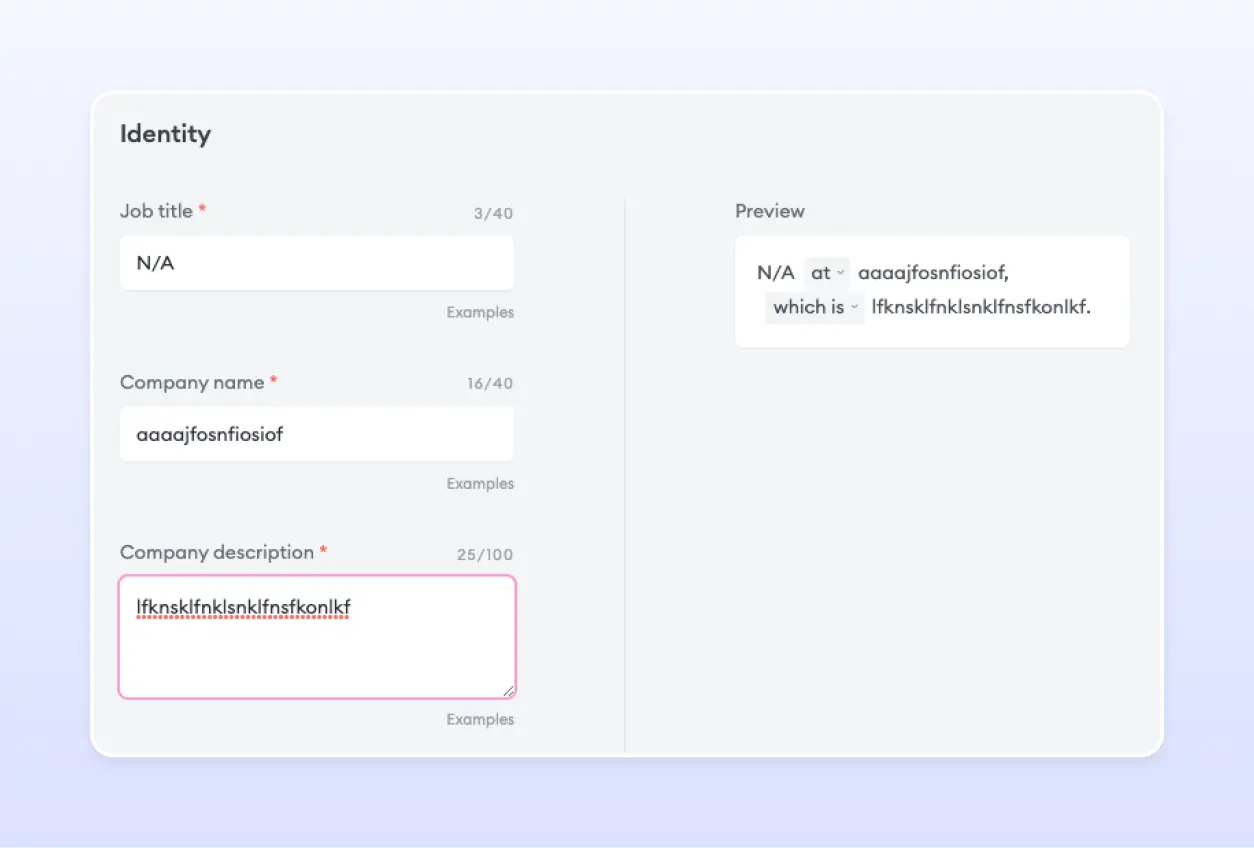
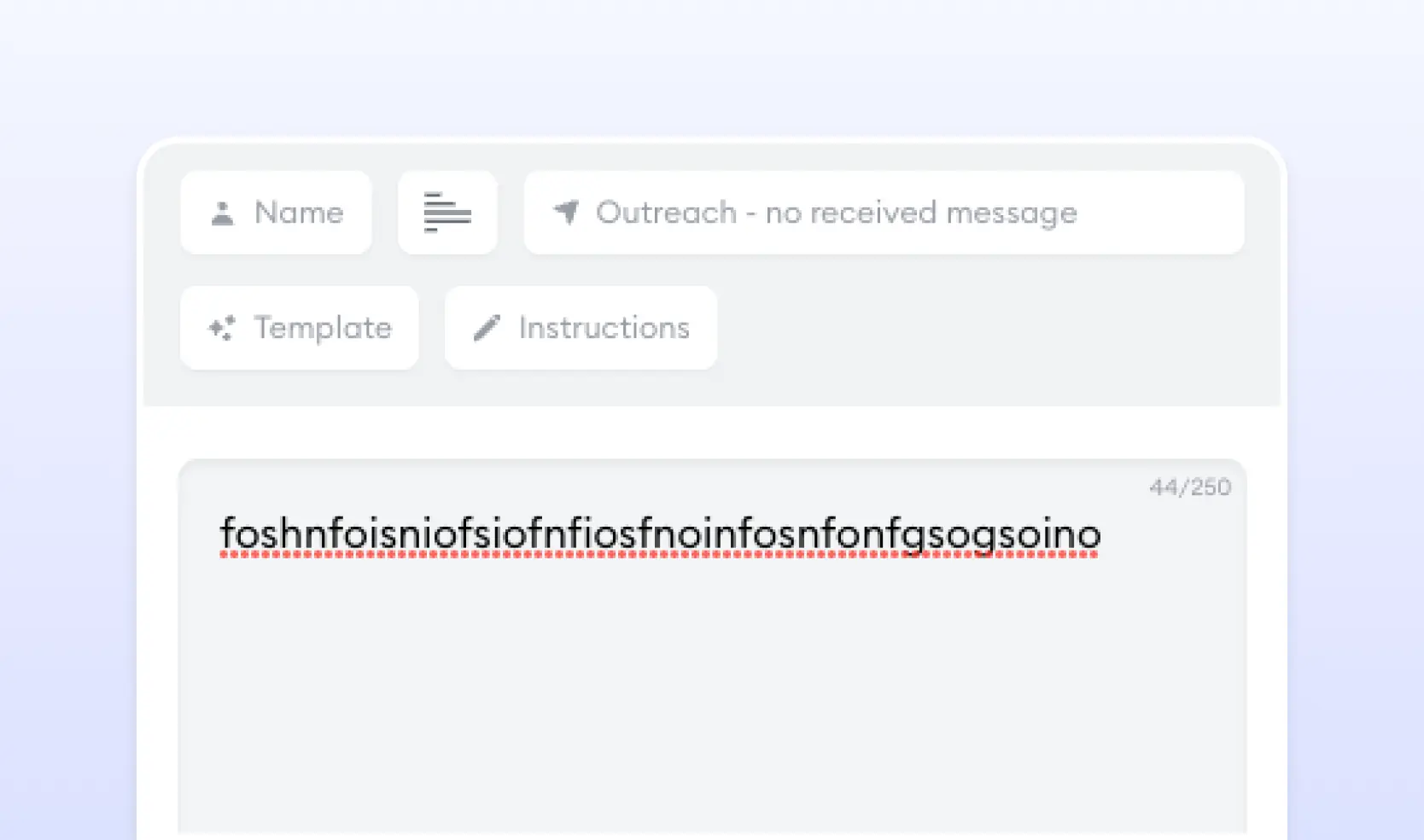
Clustering
Clustering can be an effective tool in achieving data diversity by grouping similar data points together and thus increasing the probability of creating diversity for the finetuning dataset. Clustering can help ensure that the finetuned LLM is optimized for a broad range of scenarios, making it more effective and robust towards real-world inputs.
The framing of the clustering problem would vary from case to case basis. As a Generative AI company, the north star metric for us at Flowrite was ensuring diversity and quality of amongst the distribution of our email and message generation data for finetuning. Our clustering strategy involved clustering of our email and message generation dataset.
When we started our data clustering experiments, we had to figure out what variables we wanted to use. There are lots of ways to cluster data, so we had to decide which ones would work best for us. We narrowed it down to two main factors that we thought would make a big difference in the quality of our clusters:
- Type of Embeddings
- Clustering Algorithm
We resolved to experimenting with K-means and BERTopic Clustering along with OpenAI latest embedding “text-embedding-ada-002" and Cohere embedding (both large and small variants).
Tip: Save the embeddings locally to avoid recurring costs.
Picking the Best Clusters
As clustering is an unsupervised approach, we recognized the need to incorporate a human-in-the-loop methodology to evaluate the quality of our clusters. To this end, we leveraged the expertise of our analytical linguist, who meticulously reviewed each of the clusters and selected the top two clusters that appeared to have captured the distribution of the data in the most logical and meaningful sense.
As we examined the results of our experiments, we observed that Cohere Large emerged as the most effective choice of embeddings, outperforming other options by a notable margin. Specifically, Cohere Large combined with KMeans and BERTopic clustering algorithms yielded promising results. While both Cohere Large + KMeans and Cohere Large + BERTopic performed well, we found that the latter approach yielded the most meaningful grouping of the data. In our experiments, Cohere Large + BERTopic produced clusters with fewer outliers, resulting in a more accurate and cohesive grouping of similar data points.
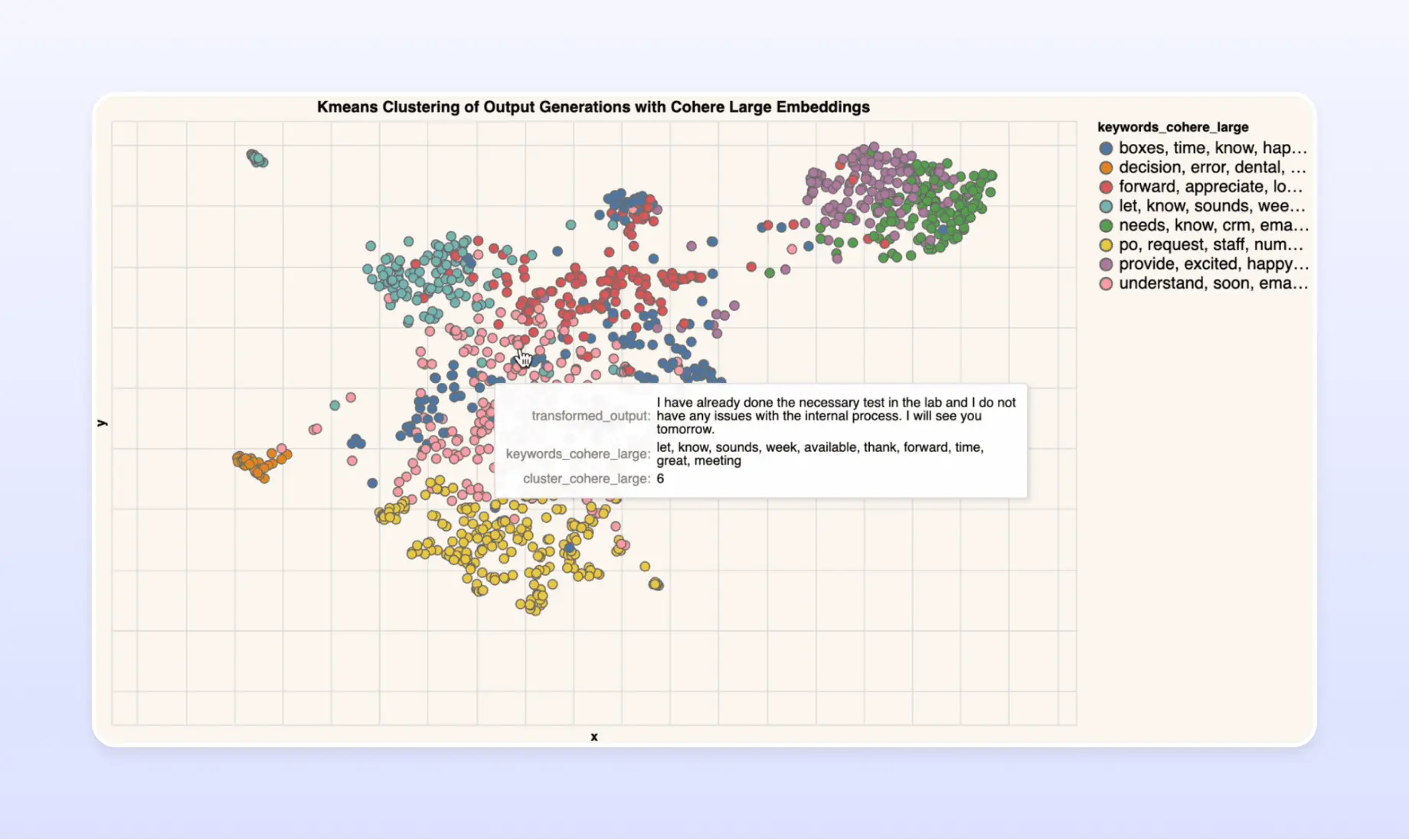
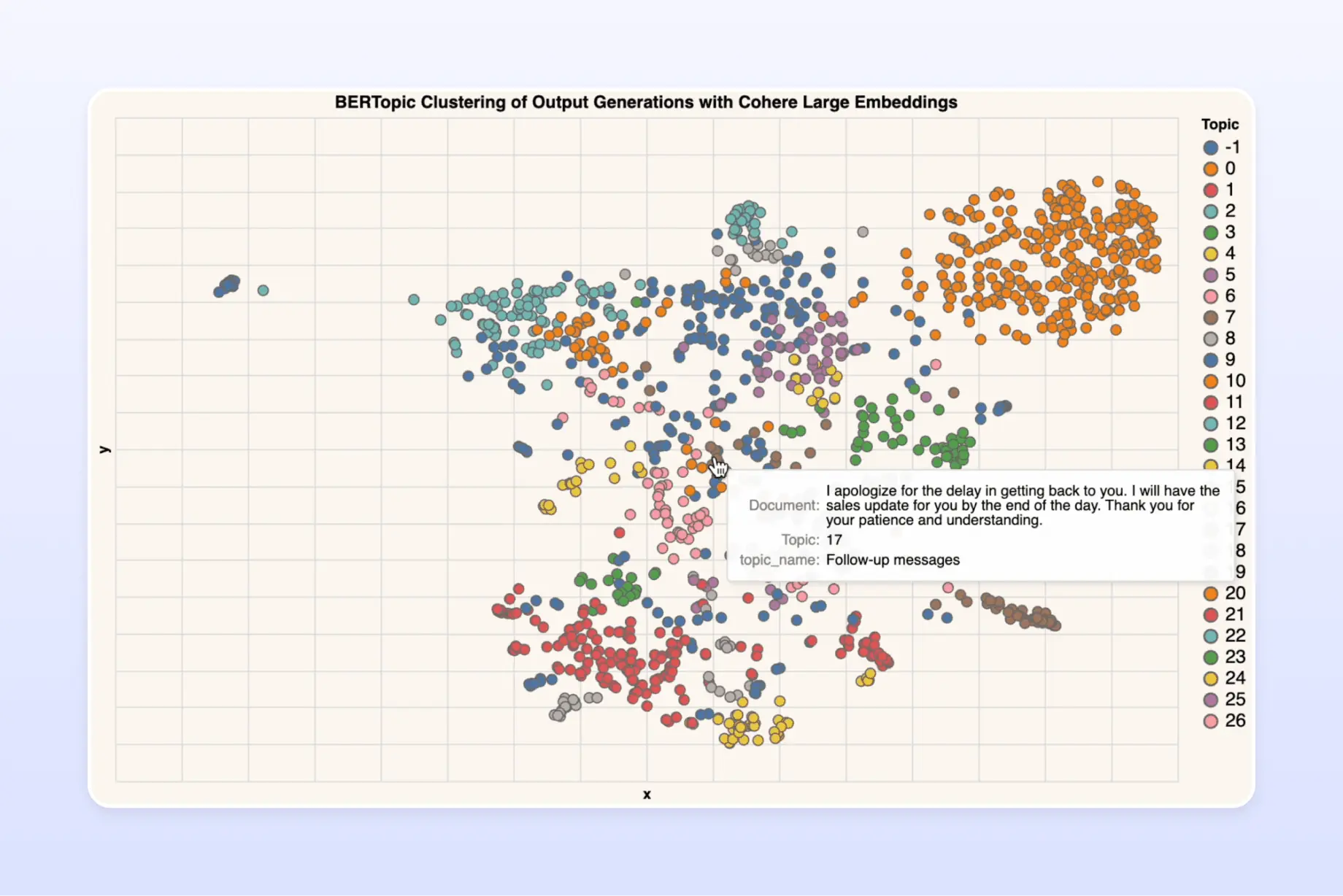
Random selection of Data from the Best Cluster
After extensive experimentation with various clustering techniques and embeddings, we settled on Cohere Large + BERTopic as our final pick of the cluster. To build a final dataset, we randomly selected 20 datapoints from each cluster, resulting in a dataset of roughly a few thousand data points. This final dataset served as the foundation for our early LLM fine-tuning efforts.
Inspired by the OpenAI’s Reinforcement Learning with Human Feedback Paper (RLHF) paper, “Training language models to follow instructions with human feedback” we set a target for 50,000 - 60,000 high quality datapoints.
To build this humongous dataset with multiple thousands of data points, we've taken an incremental approach to data preparation.This incremental approach enables us to manage the data preparation process more effectively, and to ensure that we are only adding high-quality data to the dataset. As we add more data, we can monitor the impact of each new data point on the model's performance, and adjust our approach accordingly.
By scaling the data preparation process in this manner, we can build a dataset with multiple thousands of data points that is highly relevant and accurate, and which will enable us to achieve optimal LLM fine-tuning results.
Amplifying the Signal and Minimising the noise
LLMs, such as GPT-3 and GPT-4, are stochastic, making it challenging to predict the output behavior, even if the input variables remain the same. This can occasionally result in undesirable, low-quality outputs, which can be detrimental to the overall performance of the language AI system.
At Flowrite, we recognise the importance of filtering out such cases. Despite the initial quality filters placed in our dataset preparation pipeline, we sought to ensure that poor-quality generation outputs did not compromise the quality of our final fine-tuning dataset.
As a final step, we performed a manual inspection of the data to identify and eliminate any remaining data points that did not meet our high standards for quality and accuracy.
Delivering the Final Dataset to the AI Team
After the final dataset was prepared, we needed to ensure that it was secure and efficiently available to the AI team for further processing and fine-tuning. To achieve this, we leveraged Snowflake, to store and manage the dataset.
Our Toolkit in a nutshell
- Snowflake
- Deepnote
- Data processing toolkit: Pandas, numpy
- Data Embedding Algorithms (text-embedding-ada-002 , Cohere Large and Small)
- Clustering Algorithms (KMeans and BERTopic)
- Automated Cluster Naming: Topically by Cohere
Read more
Our team has been experimenting with multiple LLMs since 2020. If you want to read more lessons we’ve learned building Flowrite, find our other blog posts on technological topics here.


