
When you build agents that operate over large enterprise datasets, you eventually hit a wall: context window overflow.
We ran into this almost immediately in developing a data-heavy agent for production.
The multi-agent system allows users to describe pricing changes in natural language, for example: "Increase all Pepsi products by 10%". The agent resolves entities, builds a structured plan, and applies changes to a database containing thousands of products.
Our initial tool implementations returned raw results from the database. A single query could return 1,000 product IDs. At roughly 35-40 characters per UUID, that is nearly 10,000 tokens consumed just to list identifiers. This excludes any agent reasoning, planning, or the overhead of multi-step workflows where sets of IDs need to flow between tools.
Once those IDs have to flow through multiple tool calls and correction loops, the number of tokens explodes. Tasks regularly failed mid-execution because the context window of the LLM was exceeded. When they did succeed, the latency was unbearable since the agent had to generate extremely long payloads for tool calls and plans:
{
"actionType": "PRICE_CHANGE",
"changeType": "IncreasePercent",
"changeValue": 10,
"productIds": [
"550e8400-e29b-41d4-a716-446655440000",
"6ba7b810-9dad-11d1-80b4-00c04fd430c8",
...
"bc678901-5678-9012-3456-789012345678" // >1000 products
]
}
We solved this by introducing KV pointers. Instead of pushing large result sets through the context window, tools return lightweight references. The data lives outside the agent's context, so it can operate on references rather than raw payloads.
This week, I came across a paper called Solving Context Window Overflow in AI Agents by IBM Research Team and realized we had independently converged on the same solution.
Context window overflow in data-intensive agents
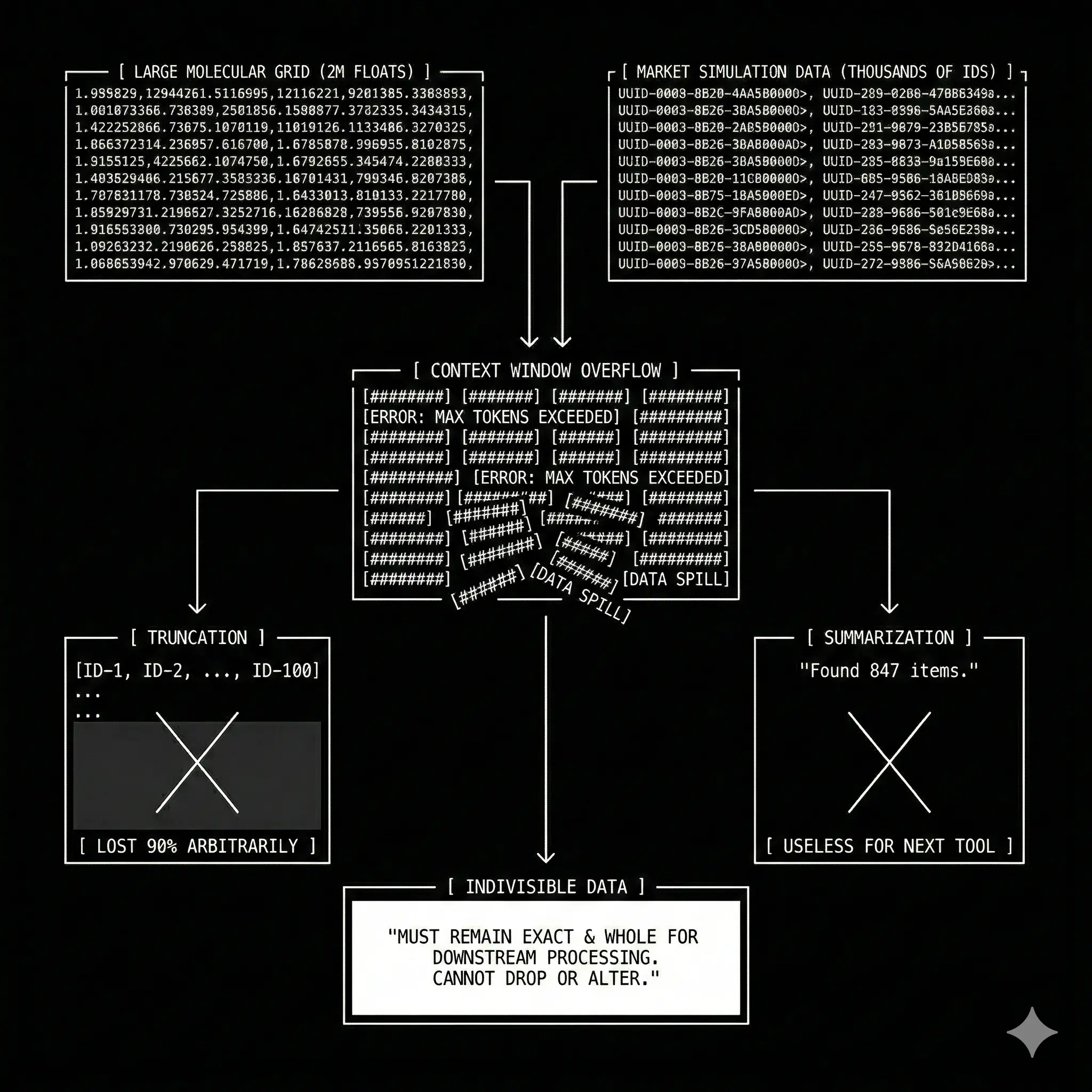
The IBM paper focuses on knowledge-intensive domains like Chemistry and Materials Science. Their agents retrieve data like molecular grids with over 2 million float elements. While our agent operates in a market simulation domain, the core problem is identical: large tool outputs fill context windows and break the execution.
Even though context window overflow is a well-known problem in LLMs, existing solutions like output truncation or summarization did not work in this case:
- Truncation: "Return only the first 100 products". But which 100? You've lost 90% of the data arbitrarily.
- Summarization: Telling the agent you "Found 847 energy drinks" is useless for the next tool that needs exact IDs to execute a change.
The paper refers to this class of outputs as indivisible data. The outputs must remain exact and whole for downstream processing. Once you drop or alter any part of them, the agent can no longer complete the task correctly.
Shifting from raw data to memory pointers
The authors of the paper propose a method that enables agents to process tool responses of arbitrary length by shifting the interaction to memory pointers. In plain terms, large outputs are stored in external memory and agents use unique IDs to reference them.
This approach delivers two benefits: 1) efficiency through dramatically fewer tokens and 2) completeness because the full output is preserved outside the agent's context.
Memory pointers
Tools store their output in external runtime memory and return only a short reference string:
Tool output: ["prod-1", "prod-2", ..., "prod-847"]
↓
Stored in memory under key: "ps-8f35a..." // ps- prefix stands for product set
↓
LLM receives: "ps-8f35a..."
Instead of returning 847 product IDs, the agent receives a tiny pointer: ps-8f35a. The underlying tool implementation accesses the full data while keeping it out of the LLM context window.
IBM's mirrored tool architecture
The IBM paper implements this using a mirrored tool architecture that comprises three components:
- Input inspector: This module detects if the arguments in a tool call payload are memory pointers or raw values. If they are pointers, it resolves them to actual data.
- Original tool: This is the underlying tool implementation that executes unchanged.
- Post-processor: This module stores large outputs in memory and returns the pointer to the agent.
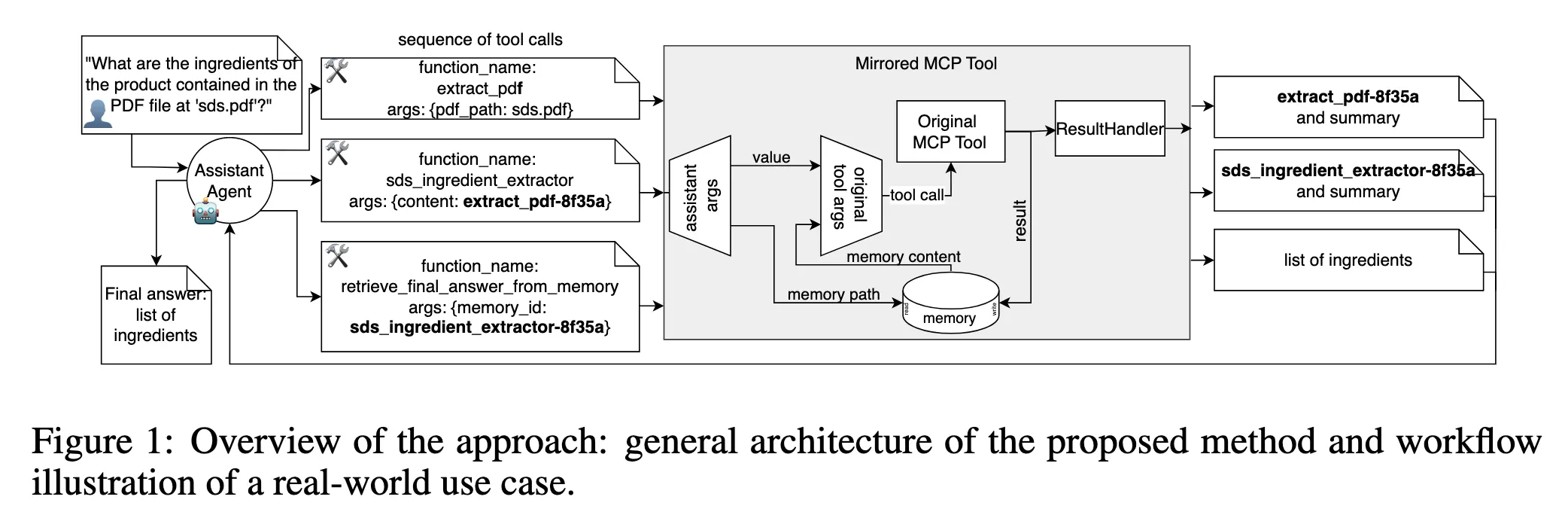
This architecture lets the wrapper handle all the pointer resolution without modifying the tool implementations.
Our implementation at Flow AI
We arrived at the same architecture through a different path. Instead of wrapping existing tools, we designed pointer-aware tools from the start.
Set IDs as memory pointers
Our resolveProductSet tool is the direct analog to the paper's memory pointer system.
When a search returns 847 products, we don't send the IDs to the LLM:
// Tool: resolveProductSet
const productSetRef = await storeProductSet({
resourceId,
productIds, // The actual 847 UUIDs—stored, not returned
matchedFilters,
});
return {
success: true,
productSetId: productSetRef.productSetId, // "ps-abc123def456" is pointer
count: productIds.length,
sampleProducts: rows.slice(0, 5),
};
The agent receives a 24-character pointer ps-abc123def456 instead of ~34,000 characters of UUIDs. As a result, the number of tokens drops by several orders of magnitude.
Glimpses for agent reasoning
The IBM paper acknowledges a limitation: pointers are opaque. How does the agent know what is behind ps-abc123def456?
We solved this with glimpses, which are compact statistical summaries attached to every pointer:
export interface ProductSetGlimpse {
productCount: number;
distributions: {
brand: DistributionEntry[];
channel: DistributionEntry[];
};
priceRange: { min: number; max: number; mean: number };
}
When resolveProductSet returns a productSetId, the agent sees both the pointer and a glimpse:
Product Set: 847 products
Channels:
store A (62%) · store b (38%)
Brands:
brand a (234) $2.49 — $4.99
brand b (198) $2.29 — $4.49
brand c (156) $1.99 — $3.99
+12 more brands...
Price Range: $1.99 — $6.99 (mean: $3.42)
This ~200-token glimpse tells the agent everything it needs to verify the search worked without loading 847 UUIDs. It can then also use other tools in the toolkit we built to inspect data from this product set to figure out for example price distributions, etc. If something looks wrong, the agent can investigate. But for the happy path, the glimpse provides sufficient confidence to proceed.
Pointers solve the storage problem, but agents also need semantic visibility into what they're manipulating. They need that to reason about intermediate steps and next actions. Glimpses provide that visibility without breaking the pointer abstraction.
Pointer-based multi-agent handoffs
We also leveraged the approach in our Plan-Execute agent architecture. Previously, our planner agent generated a full plan with every ID and scope detail. The handoff between agents was massive. Now, the planner creates a plan with pointers only:
// Planner creates plan with pointers only
storePlan({
originalQuery: "Increase all Pepsi prices by 10%",
interpretedIntent: "Apply 10% price increase to Pepsi brand products",
suggestedActions: [{
name: "Pepsi Price Increase",
productSetId: "ps-abc123def456", // Pointer, not 500 UUIDs
scopeSetId: "scope-def789", // Pointer to scope restrictions
priceChange: { type: "IncreasePercent", value: 10 }
}]
})
// Returns: planId: "plan-xyz789"
The planner outputs roughly 200 tokens. The full plan is stored server-side and associated with a planId:
const plan = await getPlan(resourceId, "plan-xyz789");
for (const action of plan.actions) {
await createAction({
productSetId: action.productSetId, // Resolved at execution time
...action.priceChange
});
}
When the executor runs, it retrieves the plan object and resolves pointers on demand. This change brought major token savings and therefore major latency improvements.
Lessons learned
Memory pointers work for small data too
Even small ID lists compound across plans, retries, and agents. A scope restriction might be 3 channel IDs, not huge. But in our case, across 10 actions in a plan, that's 30 IDs repeated in planner output and executor context. Pointers eliminate all that redundancy.
Glimpses are essential for agent reasoning
Agents need semantic visibility to verify their work. "Did I find the right products?" requires seeing something about what's behind the pointer. Glimpses are the minimal viable answer.
Latency is the real deal
Enterprise agent deployments are very sensitive to latency. Yes, we reduced token consumption by 10-20x on average. But the bigger impact was the latency improvements.
Closing thoughts
The IBM paper formalizes a pattern we discovered out of necessity: if data must be exact and large, it does not belong in the context window.
Memory pointers in data-intensive agents turn context windows back into a space for reasoning, not storage. Combined with lightweight semantic summaries, they enable agents to operate reliably over enterprise-scale databases.
We're working with customers to productize this as part of Flow AI's agent infrastructure. If you're building customer-facing, data-intensive agents and want them to scale reliably in production, let's connect.


