In this video post, we explore the exciting advancements in AI research presented by our AI Lead, Bernardo. He delves into the innovative approach of utilizing open-source language models for evaluating other language models, focusing on the research paper "Prometheus 2: An Open-Source Language Model Specialized in Evaluating Other Language Models."
The Concept of LLM-as-a-Judge
The paper is centered around the concept of LLM-as-a-judge, where large language models (LLMs) are used to evaluate the performance of other LLMs. Traditionally, closed-source proprietary models like GPT-4 or Claude have dominated this space. These models, despite their prowess, come with limitations such as lack of transparency, control, and affordability. The need for a reliable open-source alternative is apparent, and this is where Prometheus 2 steps in.
The transparency and control offered by open-source models are crucial for robust and reproducible AI research.
The Need for Open-Source Evaluators
Challenges with Closed-Source Models
- Transparency: Lack of access to model weights and training data.
- Control: Updates and changes made by the model providers without user consent can affect evaluation consistency.
- Cost: High token usage can make these models economically unfeasible for extensive evaluations.
Advantages of Open-Source Models
Open-source models, on the other hand, offer transparency and control but have struggled with low agreement with human evaluations and lack of flexibility in evaluation types.
For an in-depth discussion on the potential of open-source models, see our blog post.

Exploring the potential of open(-source) LLMs
We explore why companies initially opt for closed-source LLMs like GPT-4 and discuss the growing shift towards open LLMs.
Prometheus 2: Addressing the Challenges
Prometheus 2 aims to bridge the gap between open-source and closed-source models by achieving high correlation with human evaluations and top proprietary models like GPT-4 and Claude 3. This marks a significant improvement over previous open-source models like Prometheus 1, Llama 2, and GPT-3.5, which showed lower correlation with human judgments.
Methodology: Merging Models for Versatility
The researchers behind Prometheus 2 employed a novel methodology by merging two model-based evaluation paradigms: direct assessment and pairwise ranking. Instead of training a single model for both tasks, they trained two separate models on specific datasets for each task. The weights of these models were then merged, resulting in a more robust and flexible model that outperformed jointly trained models.
To understand the benefits of model merging in AI, read our previous post below.
Introduction to Model Merging
How can we make LLMs more versatile without extensive training? Model merging allows us to combine the strengths of multiple AI models into a single, more powerful model.
Data Creation: Synthetic Yet Effective
To train Prometheus 2, the researchers used synthetically generated datasets. They created two primary datasets:
- Feedback Collection Dataset: Used for direct assessment, it involved generating inputs and corresponding responses, which were then evaluated on a Likert scale (1 to 5).
- Preference Collection Dataset: Derived from the feedback collection dataset, this new dataset focused on pairwise ranking by presenting two responses and selecting the better one based on defined criteria.
For insights into creating effective datasets for LLMs, see our blog post on dataset engineering for LLM finetuning.

Dataset Engineering for LLM Finetuning
Our lessons on fine-tuning LLMs and how we utilise dataset engineering.
Evaluation Tasks: Direct Assessment and Pairwise Ranking
Prometheus 2's evaluation methodology included:
1. Direct Assessment
Mapping an instruction and a response to a scalar value (score) based on criteria such as reference answers and verbal feedback. This task used a Likert scale for scoring.
Example:
| Input | Response | Reference Answer | Score (1-5) | Verbal Feedback |
|---|---|---|---|---|
| Explain quantum computing in simple terms. | Quantum computing uses quantum bits... | Quantum computing leverages quantum mechanics... | 4 | Good explanation, but could be simplified further. |
2. Pairwise Ranking
Comparing two responses to an instruction and selecting the better one, again using reference answers and verbal feedback for higher correlation with human judgments.
Example:
| Input | Response A | Response B | Reference Answer | Chosen Response | Verbal Feedback |
|---|---|---|---|---|---|
| Explain quantum computing in simple terms. | Quantum computing uses quantum bits... | Quantum computing leverages quantum mechanics... | Quantum computing uses quantum mechanics... | B | Response B uses more accurate terminology. |
Results: High Correlation and Strong Performance
The evaluation of Prometheus 2 revealed that both the 7B and 8x7B models strongly correlate with reference evaluators like GPT-4, Claude, and human judgments, with Pearson correlation scores often exceeding 0.5. This indicates a moderate to high agreement, showcasing Prometheus 2 as a strong contender among open-source evaluators.
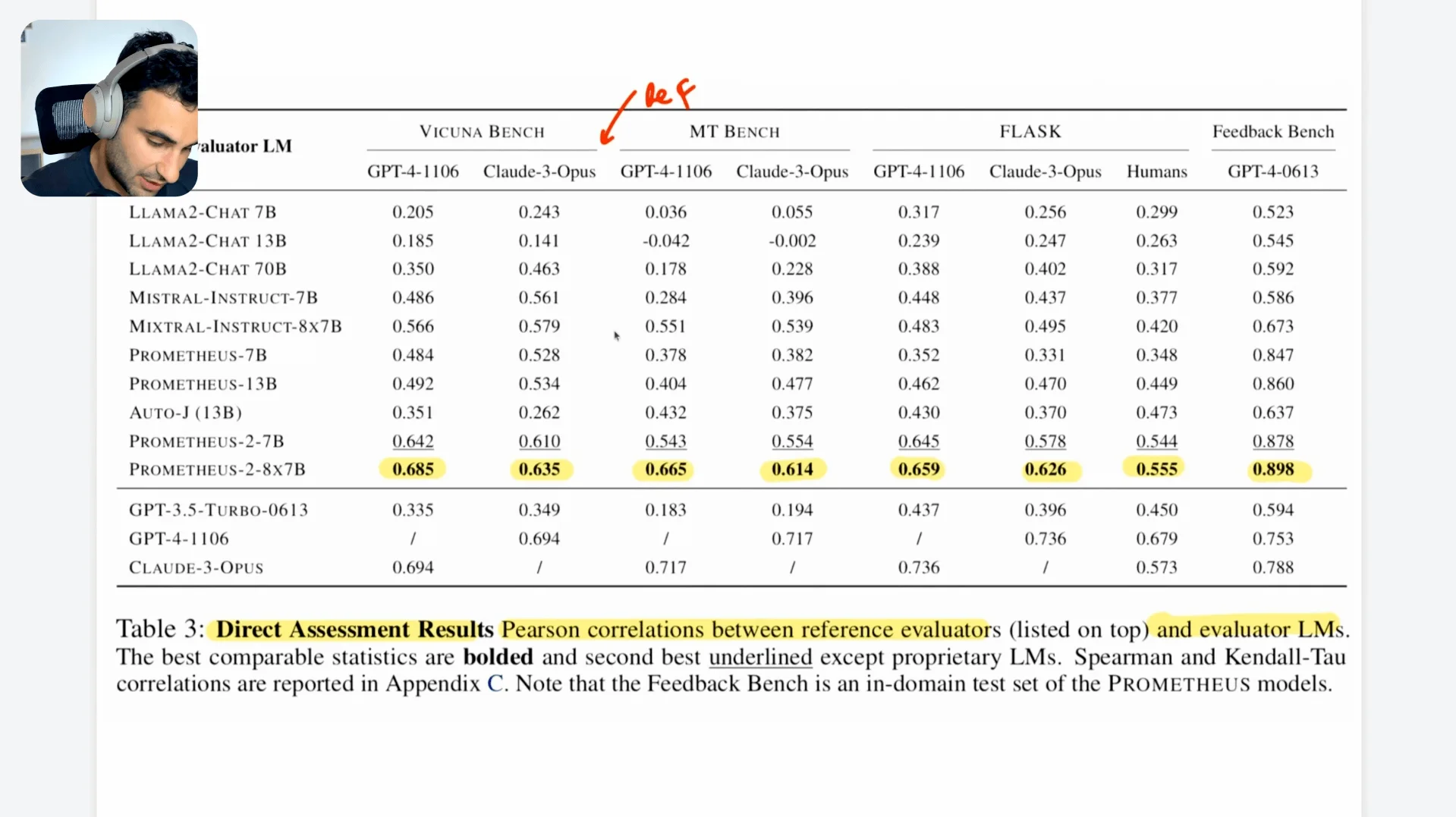
Conclusion: A Step Forward for Open-Source Evaluators
The research presented in the Prometheus 2 paper signifies a significant advancement in developing reliable open-source LLM evaluators. By achieving high correlation with closed-source models and human evaluations, Prometheus 2 paves the way for more transparent, controllable, and affordable LLM evaluations.
For a detailed analysis of LLM evaluation, read our two-part series: LLM Evaluation (1/2) — Overcoming Evaluation Challenges in Text Generation and LLM Evaluation (2/2) — Harnessing LLMs for Evaluating Text Generation.


