
Introduction
In September 2024, we introduced Flow-Judge-v0.1, a compact 3.8B parameter open evaluator model for assessing LLM systems. Built on the Phi-3.5 Instruct model, Flow-Judge-v0.1 was fine-tuned on a synthetic dataset, demonstrating that smaller models could perform comparably to larger ones in held-out and out-of-domain benchmarks.
Since then, small open-source language models have advanced rapidly, with significant improvements in capability and evaluation performance. Having previously fine-tuned Flow-Judge on Phi-3.5, we wanted to explore the evaluation potential of Microsoft's newly released Phi-4. This blog post outlines a small experiment we conducted to assess Phi-4's performance.
Experimentation
1. Baseline Benchmarks
For this experiment, we used the Unsloth version of Phi-4, which includes bug fixes, accuracy improvements, and optimizations for fine-tuning. We benchmarked Phi-4 against the evaluation tasks used in Flow-Judge v0.1, running tests with our private fork of lm-evaluation-harness. These tasks included our in-domain datasets and widely used benchmarks such as RagTruth, HaluBench, and FeedbackBench.
Phi-4, a 14B parameter model, performed well across benchmarks, slightly surpassing or matching the specialized Flow-Judge v0.1 (3.8B). This suggests that Phi-4 could be a strong candidate for LLM-as-a-judge tasks. However, even with powerful models like Phi-4, grounding and alignment remain essential for producing reliable and meaningful evaluations.
| 3-Likert Held-out Test set | 5-Likert Held-out Test set | |||||
|---|---|---|---|---|---|---|
| Evaluator | pearsonr | spearmanr | kendall-tau | pearsonr | spearmanr | kendall-tau |
| microsoft/Phi-3.5-mini-instruct | 0.756 | 0.749 | 0.695 | 0.808 | 0.819 | 0.739 |
| prometheus-eval/prometheus-7b-v2.0* | - | - | - | 0.910 | 0.908 | 0.838 |
| meta-llama/Meta-Llama-3.1-8B-Instruct | 0.836 | 0.833 | 0.789 | 0.854 | 0.868 | 0.791 |
| mistralai/Mistral-Nemo-Instruct-2407 | 0.813 | 0.807 | 0.758 | 0.870 | 0.867 | 0.789 |
| gpt-4o-mini | 0.890 | 0.888 | 0.851 | 0.923 | 0.923 | 0.864 |
| flowaicom/Flow-Judge-v0.1 | 0.888 | 0.888 | 0.852 | 0.919 | 0.919 | 0.856 |
| unsloth/phi-4 | 0.891 | 0.890 | 0.852 | 0.923 | 0.928 | 0.868 |
| Feedback bench | |||
|---|---|---|---|
| Evaluator | pearsonr | spearmanr | kendall-tau |
| microsoft/Phi-3.5-mini-instruct | 0.710 | 0.721 | 0.622 |
| prometheus-eval/prometheus-7b-v2.0* | 0.878 | 0.909 | 0.773 |
| meta-llama/Meta-Llama-3.1-8B-Instruct | 0.742 | 0.749 | 0.654 |
| mistralai/Mistral-Nemo-Instruct-2407 | 0.720 | 0.724 | 0.632 |
| gpt-4o-mini | 0.797 | 0.795 | 0.701 |
| flowaicom/Flow-Judge-v0.1 | 0.787 | 0.789 | 0.688 |
| unsloth/phi-4 | 0.787 | 0.793 | 0.699 |
| RAGTruth QA | RAGTruth Data-to-Text | RAGTruth Summarization | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Evaluator | Precision | Recall | F1 | Precision | Recall | F1 | Precision | Recall | F1 |
| microsoft/Phi-3.5-mini-instruct | 0.817 | 0.963 | 0.884 | 0.356 | 1.000 | 0.525 | 0.776 | 1.000 | 0.874 |
| meta-llama/Meta-Llama-3.1-8B-Instruct | 0.844 | 0.986 | 0.910 | 0.382 | 0.537 | 0.447 | 0.797 | 0.940 | 0.863 |
| mistralai/Mistral-Nemo-Instruct-2407 | 0.821 | 0.995 | 0.900 | 0.357 | 1.000 | 0.526 | 0.775 | 1.000 | 0.873 |
| gpt-4o-mini | 0.830 | 0.966 | 0.893 | 0.398 | 0.994 | 0.569 | 0.786 | 0.997 | 0.879 |
| flowaicom/Flow-Judge-v0.1 | 0.835 | 0.961 | 0.894 | 0.541 | 0.249 | 0.341 | 0.834 | 0.836 | 0.835 |
| unsloth/phi-4 | 0.847 | 0.953 | 0.897 | 0.426 | 0.944 | 0.587 | 0.814 | 0.991 | 0.894 |
| HaluEval | Covid-QA | PubMedQA | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Evaluator | Precision | Recall | F1 | Accuracy | Precision | Recall | F1 | Accuracy | Precision | Recall | F1 | Accuracy |
| microsoft/Phi-3.5-mini-instruct | 0.730 | 0.914 | 0.812 | 0.788 | 0.617 | 0.964 | 0.752 | 0.681 | 0.623 | 0.986 | 0.764 | 0.696 |
| meta-llama/Meta-Llama-3.1-8B-Instruct | 0.864 | 0.891 | 0.878 | 0.874 | 0.663 | 0.976 | 0.790 | 0.734 | 0.681 | 0.962 | 0.797 | 0.750 |
| mistralai/Mistral-Nemo-Instruct-2407 | 0.655 | 0.993 | 0.789 | 0.735 | 0.651 | 0.982 | 0.783 | 0.728 | 0.602 | 0.994 | 0.750 | 0.669 |
| gpt-4o-mini | 0.846 | 0.940 | 0.891 | 0.885 | 0.795 | 0.964 | 0.872 | 0.858 | 0.791 | 0.904 | 0.843 | 0.832 |
| flowaicom/Flow-Judge-v0.1 | 0.826 | 0.895 | 0.859 | 0.854 | 0.767 | 0.877 | 0.818 | 0.807 | 0.874 | 0.624 | 0.728 | 0.767 |
| unsloth/phi-4 | 0.861 | 0.907 | 0.883 | 0.880 | 0.855 | 0.962 | 0.905 | 0.900 | 0.857 | 0.884 | 0.870 | 0.868 |
| gpt-4o* | - | - | - | 0.879 | - | - | - | 0.821 | - | - | - | 0.821 |
| Claude 3 Sonnet* | - | - | - | 0.845 | - | - | - | 0.829 | - | - | - | 0.829 |
| RAGAS Faithfulness* | - | - | - | 0.706 | - | - | - | 0.750 | - | - | - | 0.669 |
| Lynx 8B* | - | - | - | 0.857 | - | - | - | 0.963 | - | - | - | 0.852 |
| Lynx 70B* | - | - | - | 0.884 | - | - | - | 0.975 | - | - | - | 0.904 |
2. Fine-Tuning Experiments
Since Phi-4 performed well out-of-the-box, we tested whether a quick fine-tuning experiment could yield further improvements. We employed a similar finetuning strategy as before with Flow-Judge v0.1 but this time quantized. We utilized Rank-Stabilized QLoRA with three GPUs using Deepspeed.
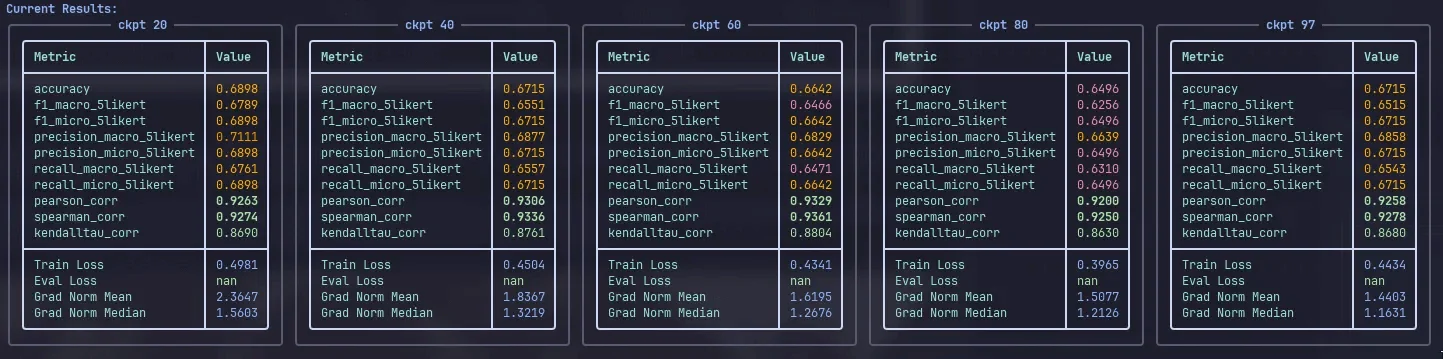
To find the best resulting model, we used multiple separate hyperparameter runs and frequent checkpointing and intensive post-evaluation to search for the overall balanced and best performing checkpoint. Our search started from evaluating everything on five-point Likert task and based on those results assessing the promising runs and checkpoint areas and their three-point and binary performance.
Fine-Tuning Stages
1. Rank Optimization
We tested ranks 64, 128, and 256 with a stable learning rate of 1e-5 and 5 epochs, using an alpha ratio of 2:1. Additionally, we experimented with ADEMAMIX, a modified Adam optimizer designed to better leverage past gradients.
While results were largely unchanged, rank 256 performed best and was selected for further tuning. Additionally, we observed some positive bumps near the end of epoch, which may suggest that there might be an optimal zone, that we could try to identify in stage 2.
2. Learning Rate and Epoch Adjustment
As the learning rate 1e-5 seemed conservative and we observed no overfitting but also minimal gains, we tested higher learning rates (2e-5) with fewer epochs (2). No improvements were identified from this stage.
3. Optimizer and Overfitting Attempts
We reverted to ADAMW to isolate ADEMAMIX's impact and experimented with increased learning rates (up to 5e-5) and varied epochs to encourage overfitting. However, the results remained inconsistent, fluctuating without a clear trend in either direction.
These fine-tuning experiments did not significantly improve Phi-4's already strong evaluation capabilities. The model's advanced reasoning and instruction-following skills suggest that our training datasets provided little additional signal beyond what it had already learned.
Conclusion
This experiment provided insights into the current capabilities of small open-source models as evaluators. Phi-4 performed well in evaluation tasks without fine-tuning, suggesting that newer models can be increasingly robust out-of-the-box. Our fine-tuning attempts, while exploratory rather than fully optimized, did not yield significant improvements, indicating that the model already captures much of what our dataset aimed to reinforce.
Our experiments with smaller models like Llama 3.2 1B Instruct have shown that fine-tuning can lead to meaningful gains, positioning them as strong candidates for specialized evaluators where efficiency is key. While they may not offer the broad capabilities of larger models for general-purpose judging, the results indicate that with fine-tuning, smaller LMs can be highly effective for targeted evaluation tasks. This opens up opportunities for using these models in contexts that demand efficiency and focused performance. We'll be exploring this direction further in a future post.
Overall, small open-source models show promise as their general capabilities continue to improve. Their accessibility allows for experimentation, fine-tuning, and adaptation to specific evaluation tasks, while their transparent nature makes them easier to study and refine. As these models evolve, they may become increasingly viable alternatives for LLM evaluation, especially in contexts where control, customization, efficiency and reproducibility are important.
Regardless of the model used, ensuring proper grounding and alignment with human judgment remains essential for building reliable evaluators. This remains an ongoing focus as we continue exploring the role of LLMs in evaluating and refining AI systems.


